本文提出了 CT-1 (Camera Transformer 1),这是一种新型的视觉-语言-相机 (VLC) 模型,旨在将空间推理能力转移到视频生成任务中。通过结合 Diffusion Transformer 和基于小波的正则化损失 (Wavelet-based Regularization Loss),CT-1 能够根据参考图像和文本指令精准预测相机轨迹,并在 CameraBench 上实现了 25.7% 的相机控制准確率提升。
TL;DR
在视频生成领域,如何让相机像专业摄影师一样按照导演意图(文本)和转场需求(场景)精准移动?复旦大学与腾讯等团队提出的 CT-1 (Camera Transformer 1) 给出了答案。它不仅是一个视频生成模型,更是一个具备“空间推理”能力的视觉-语言-相机 (VLC) 专家,能将模糊的指令转化为精确的 3D 轨迹,使控制精度大幅提升 25.7%。
痛点深挖:导演意图与参数配置的断层
目前的相机控制方法存在两个极端:
- 语义模糊性:像 Sora 或 Wan2.1 这种模型虽然支持文本控制,但在处理“向左平移并同时前推”这种复合动作时,常常表现得像“听不懂话”,运动轨迹随机且扭曲。
- 人工依赖:像 CameraCtrl 需要用户手动输入精确的相机外参矩阵。对于普通用户来说,这几乎是不可能完成的任务。
CT-1 的核心直觉:相机运动不应只是像素的平移,它必须基于对场景深度、物体布局的空间推理。
核心架构:Diffusion Transformer + 小波域正则化
CT-1 的设计极为精巧,分为语义嵌入、分布建模和视频生成三个阶段。
1. 视觉-语言双引擎
CT-1 采用了双支路视觉编码器(DINOv2 + SigLIP)来兼顾局部细节与全局语义。最关键的设计是引入了一个特殊的 <CAM> token,它在 LLaMA-2 骨干网络中吸收视觉和文本信息,作为后续轨迹生成的“精神支柱”。
2. 轨迹建模:为什么是 Diffusion?
传统的回归模型倾向于输出“平均轨迹”,导致运动死板。CT-1 意识到:同一条指令在不同场景下对应无数种合理的运动。因此,它使用 Diffusion Transformer (DiT) 来学习相机轨迹的概率分布,确保生成的轨迹既符合物理逻辑又具有多样性。
3. WavReg:频域的降维打击
为了防止相机运动出现抖动(高频噪声),作者提出了基于小波的正则化损失 (WavReg)。
- 低频部分:捕捉全局运动趋势(如:相机正在向前走)。
- 高频部分:捕捉局部微动或干扰。 通过在训练中给予低频分量更大的权重系数,模型被诱导学习更平滑、更具结构性的轨迹。
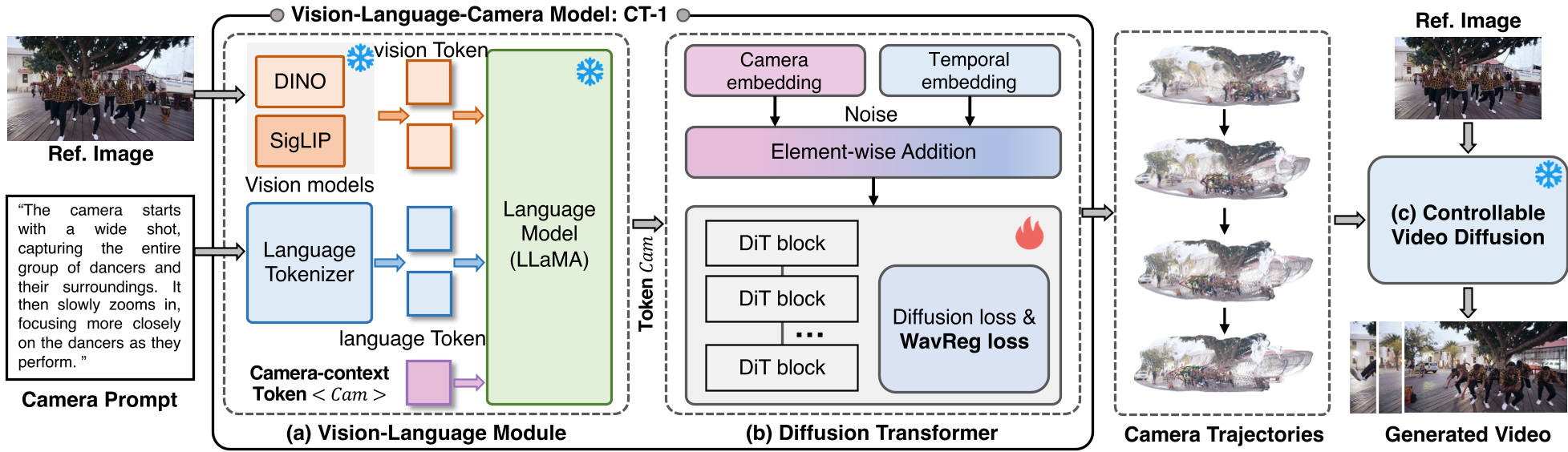 图 1:CT-1 整体架构:从多模态输入到 DiT 轨迹生成,再到视频合成的流水线。
图 1:CT-1 整体架构:从多模态输入到 DiT 轨迹生成,再到视频合成的流水线。
实验与结果:全方位的跨越
研发团队构建了 CT-200K 数据集,包含 4700 万帧视频,涵盖了从日常生活到复杂驾驶场景的丰富数据。
1. 相机控制大胜
在 CameraBench100 测试中,CT-1 的平均成功率达到了 81.6%。对比目前最强的开源模型 Wan2.2,CT-1 在处理“复杂运动”分类下展现出断代式的领先优势。
2. 消融实验证明 WavReg 的有效性
实验表明,当 β(小波正则化权重)设定为 0.1 时,模型的成像质量和运动平滑度达到最优平衡。这验证了在物理轨迹建模中,频域约束远比单纯的时域平滑(如速度/加速度惩罚)更有效。
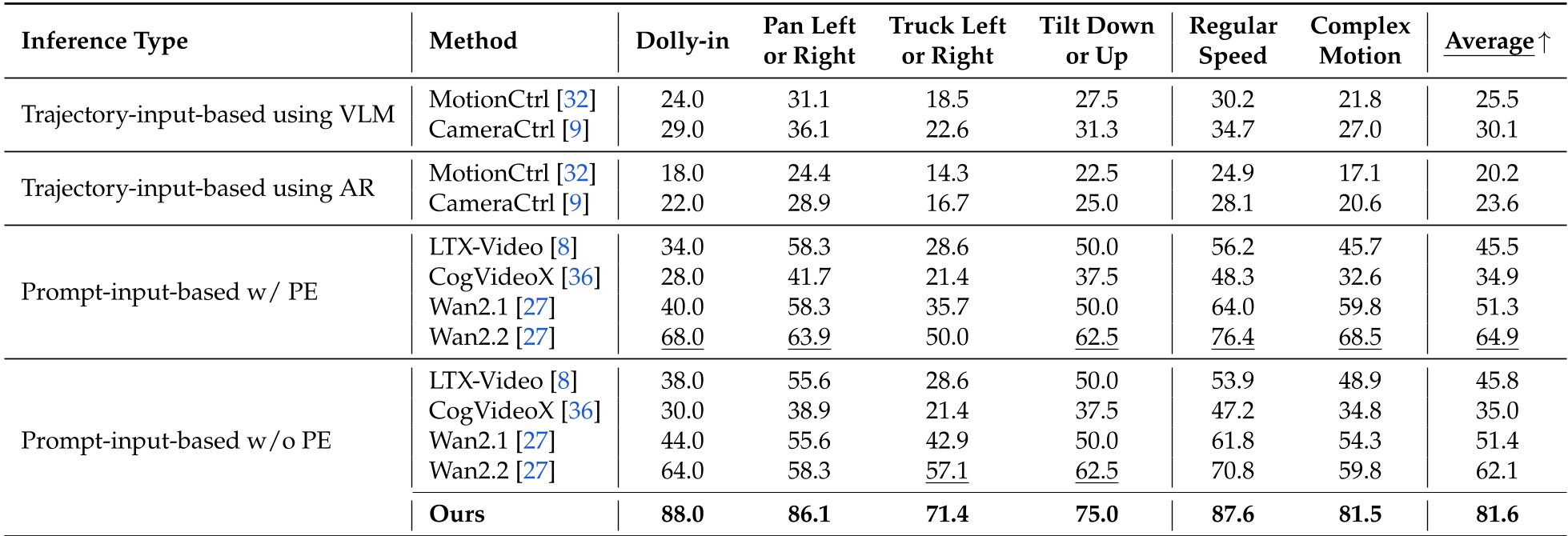 表 1:CT-1 在各种运动类型下的成功率对比,其 Average 值显著优于竞争对手。
表 1:CT-1 在各种运动类型下的成功率对比,其 Average 值显著优于竞争对手。
深度洞察与总结
CT-1 的成功标志着视频生成正在从“像素模拟”向“物理推理”进化。其模块化设计极具前瞻性:CT-1 预测出的轨迹可以直接插入现有的 CameraCtrl 或 MotionCtrl 插件中,成为一种通用的“相机大脑”。
局限性:尽管 CT-1 在空间推理上表现优异,但在处理极致动态的物体(如高速碰撞)时,相机轨迹与物体交互的协同推理仍有提升空间。
未来启示:这一工作预示着,未来的 Generative World Models 将不再仅仅依赖海量像素的喂养,而是通过引入像 CT-1 这样具有显式几何感知能力的微调模块,实现真正的“导演级”控制。