本文提出了 Visually-grounded Humanoid Agents,一个能够仅凭视觉观测和目标指令在复杂 3D 场景中自主行动的双层架构。该系统结合了基于 3D Gaussian Splatting (3DGS) 的语义场景重建(World Layer)和基于多模态大模型 (VLM) 的具身智能体感知-决策-执行环路(Agent Layer),首次在超大规模户外场景实现了具有物理常识和迭代推理能力的拟人智能体。
核心速览
TL;DR:北京大学与多家机构联合提出了一种名为 Visually-grounded Humanoid Agents 的双层范式。该系统不需要特权信息,开发者只需提供单目视频,系统便能自动重建高精细度的 3D 语义世界,并让数字人在其中像真人一样观察、推理、规划并执行全身体动作。
背景定位:这不仅仅是一次 SOTA 的刷新,更是在数字人研究中引入了“具身 AI (Embodied AI)”的核心灵魂。它将 CV 的场景重建(3DGS)、NLP 的推理(VLM)与 CG 的动作生成(Diffusion)完美缝合,是数字孪生向“数字原生”演进的关键一步。
痛点深挖
为什么现有的数字人总显得“傻憨”?
- 缺乏主观视角:它们大多运行在上帝视角下,一旦进入没有全局地图的新场景就“抓瞎”。
- 感知与动作断层:高层的语义理解(去买咖啡)与底层的电机控制(左脚抬高 10 厘米)之间存在巨大的 Gap,传统的 LLM 很难直接输出物理可执行的连续控制信号。
- 环境交互失真:室外场景极其复杂,遮挡(Occlusion)频繁,现有的语义地图在处理“车后藏着的消防栓”时往往失效。
方法论详解:World-Agent 双层范式
1. World Layer: 遮挡感知的 3D 语义地基
作者对 3D Gaussian Splatting (3DGS) 进行了魔改。核心创新在于引入了遮挡感知掩码(Occlusion-Aware Masks)。
- 原理:在训练 3D 语义特征时,系统会预先计算每个视角下的遮挡关系。如果是被挡住的部分,则不参与该视角的特征学习。
- 自动化标注:结合 Qwen2.5-VL 等模型,通过“背景调暗、目标高亮”的视觉提示技巧,系统能自动为场景中的每一个路灯、长椅生成细致的语义描述。
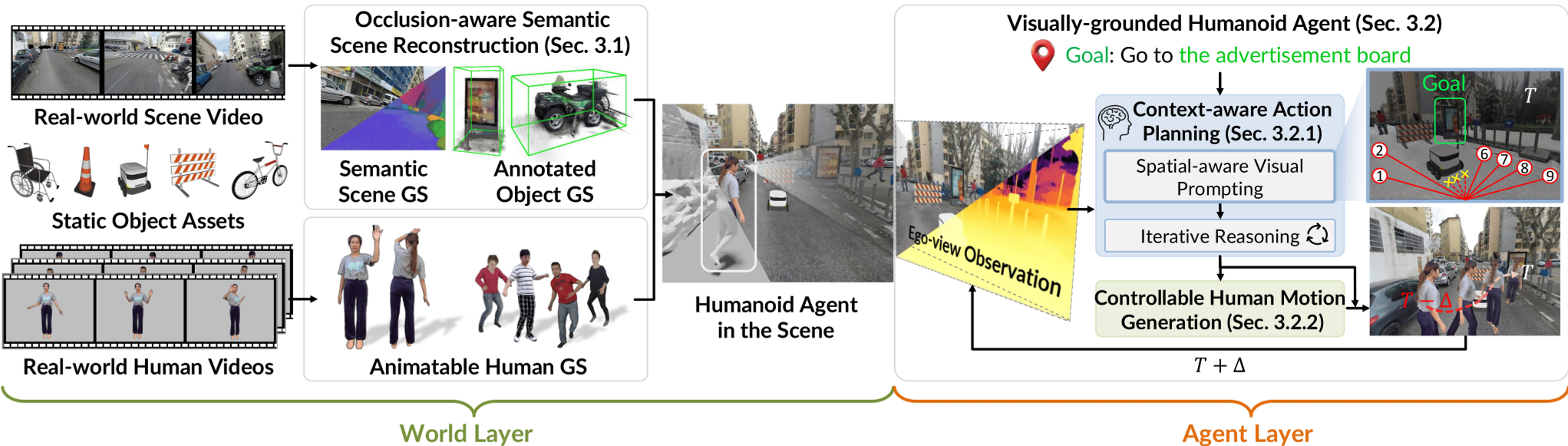 图 1: 整体框架 - 从单目视频到自主智能体的双层演进
图 1: 整体框架 - 从单目视频到自主智能体的双层演进
2. Agent Layer: “慢思考”与“快执行”
受人类认知启发,系统将决策分为两级:
- 感知与迭代推理 (Slow Thinking):智能体接收第一人称 RGB-D 输入,在图像上叠加空间感知箭头(这些箭头是根据深度图计算出的、物理可达的方向)。VLM 不需要输出坐标,只需从预设的“动作原语(Action Primitives)”中选一个。
- 全身体动作生成 (Fast Execution):选定目标点后,底层的 Motion Diffusion Model 负责把“走到那儿”翻译成符合 SMPL 人体动力学的全身体姿态序列,并利用训练推理(Training-free Guidance)确保脚踏实地。
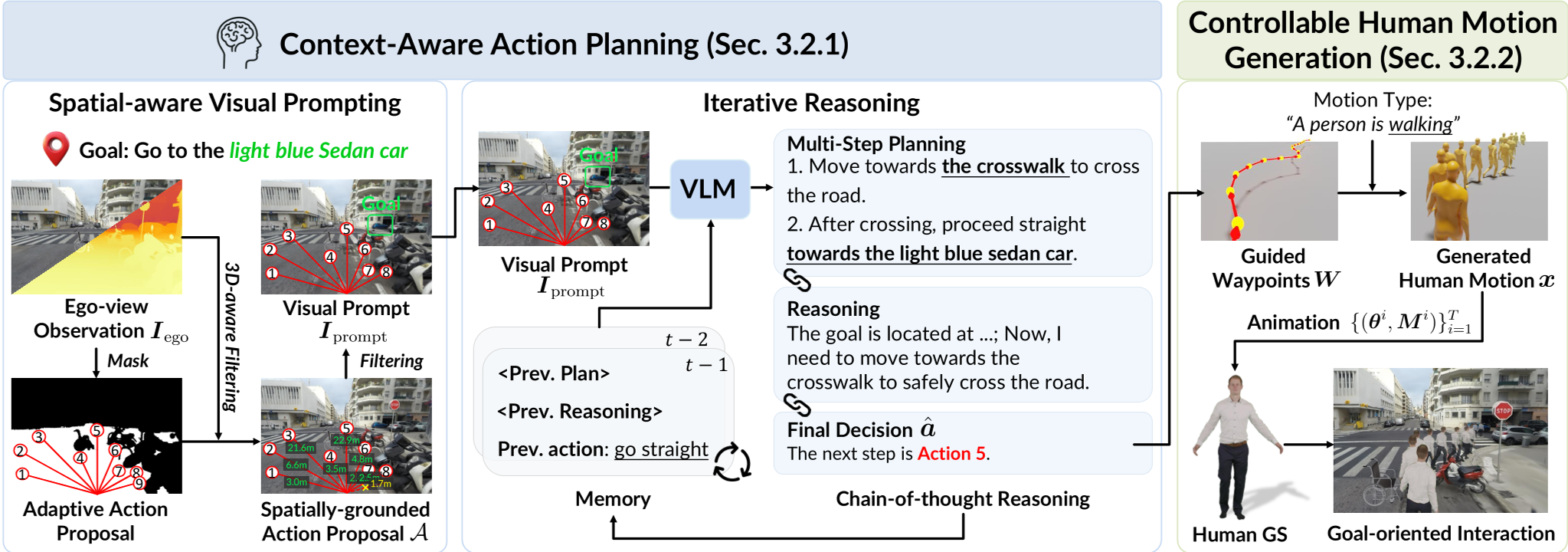 图 2: 智能体层细节 - 空间视觉提示与动作生成的闭环
图 2: 智能体层细节 - 空间视觉提示与动作生成的闭环
实验与结果
在名为 SmallCity 的大规模城市场景(100m x 100m)中,研究团队设计了三级挑战:
- SimNav:基础导航。
- ObstNav:静态避障(在必经之路上放屏障)。
- SocialNav:动态避障(避让其他正在行走的数字人)。
关键战绩:
- 在避障测试中,该方法不仅成功率更高,而且路径加权成功率 (SPL) 遥遥领先,表明智能体不仅能到,而且走得更顺滑。
- 消融实验显示:如果没有“空间感知提示”,智能体经常会撞墙(CR 飙升至 50% 以上);如果没有“迭代推理”,智能体会表现得非常近视,为了避开前面的车而彻底忘记目标在哪。
 图 3: 世界层消融实验展示了遮挡处理对语义精细度的改善
图 3: 世界层消融实验展示了遮挡处理对语义精细度的改善
深度洞察与总结
主编观点: 本文最惊艳的地方在于它对 VLM “幻觉”与“空间感缺失”的系统性对抗。通过将复杂的 3D 导航降维成 VLM 最擅长的“选择题”,并辅以物理可达性过滤,作者在不进行大规模端到端强化学习的前提下,达到了惊人的自主性。
局限性: 目前的渲染虽然达到了 60+ FPS,但 VLM 的推理延迟(约 1 秒/步)仍是实时交互的瓶颈。此外,对于复杂的精细物体交互(如开门、递杯子)仍有待进一步探索,这需要解决更细粒度的接触物理模拟。
未来 outlook: 随着多模态模型推理速度的提升,这种“第一人称视角 + 离散动作原语”的框架极有可能成为人形机器人或 VR 虚拟居民的标准配置。