本文提出了 Visually-Guided Policy Optimization (VGPO) 框架,旨在增强多模态大模型(VLMs)在强化学习过程中的视觉忠实度。通过利用模型内部隐状态计算“视觉关注度分数”,该方法在不依赖外部模型的情况下,实现了 SOTA 级别的多模态数学与视觉逻辑推理性能。
TL;DR
在多模态推理中,模型往往开头“看一眼”图片,后面就开始胡编乱造。这篇来自阿里巴巴 AMAP 团队、中山大学及北邮的研究提出了 VGPO (Visually-Guided Policy Optimization)。它无需外部教练(如 GPT-4),仅靠模型自身的隐状态相似度检测“视觉关注度”,并通过一套补偿机制在强化学习中强制让模型在推理后期也“盯着”图片看。
核心洞察:多模态推理中的“间歇性失明”
研究团队通过对 Qwen2.5-VL 等模型进行深度剖析,发现了多模态推理的三大痛点:
- 文本主导 (Text-dominated):模型生成的 Token 绝大部分注意力都给了之前的文本,视觉 Token 的激活极其稀疏。
- 时间维度视觉遗忘 (Temporal Visual Forgetting):随着推理步骤(Reasoning Steps)增加,对视觉输入的注意力呈线性衰减。
- 正确性与视觉积累正相关:实验证明,推理正确的样本,其后期与前期的视觉激活比例明显高于错误样本(0.680 vs. 0.532)。
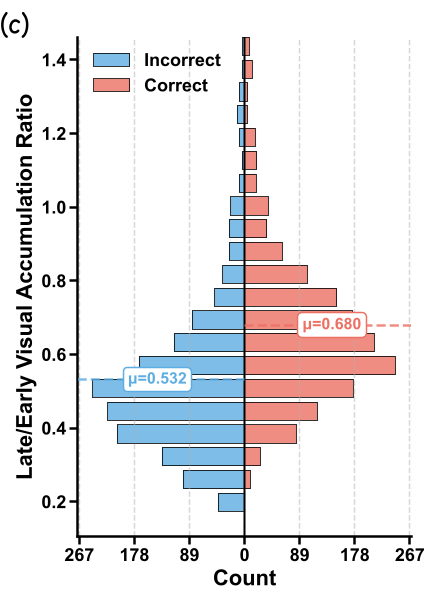 可以看到,红色线条代表的视觉注意力在后期显著下降。
可以看到,红色线条代表的视觉注意力在后期显著下降。
方法论:如何原地自救?
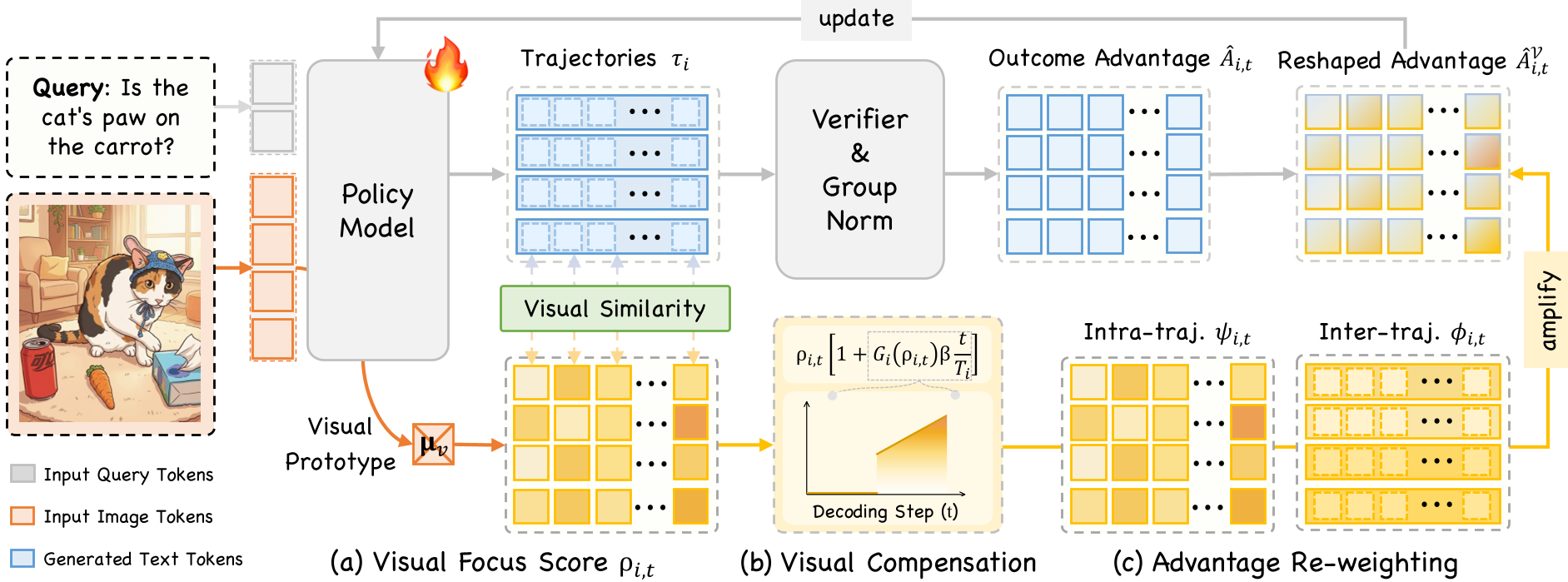
VGPO 的核心在于不需要外部干预。作者发现模型的内部隐状态(Hidden States)其实已经包含了“这个 Token 是否在引用图片”的信息。
1. 视觉关注度分数 (Visual Focus Score)
模型将生成的文本 Token 与输入图片的视觉原型(Visual Prototype)计算余弦相似度。如果相似度高,说明这个词是在“看图说话”。
2. 视觉关注度补偿机制 (VAC)
为了对抗“遗忘”,作者引入了一个线性补偿项:步数越靠后,对视觉相似度的要求和奖励就越高。公式如下: 这强迫模型在长推理链条的末端依然保持视觉灵敏度。
3. 双粒度优势重加权 (Dual-grained Advantage Re-weighting)
这是 VGPO 的工程精髓。它在 GRPO 的基础上对优势函数 进行了重塑:
- Intra-trajectory (轨迹内):奖励那些在推理关键节点表现出高视觉激活的 Token。
- Inter-trajectory (轨迹间):在整个采样组(Group)中,优先选择整体视觉积累更多的推理路径。
实验战绩:小模型逆袭
VGPO 在多个硬核榜单(MathVista, LogicVista 等)上刷新了记录。最引人注目的是,经过 VGPO 训练的 Qwen2.5-VL-7B,在数学推理上的平均表现(66.6%)竟然超过了未经过此优化的 Qwen2.5-VL-72B。
| 模型 | MathVista | Avg-Math | Avg-Vision | | :--- | :---: | :---: | :---: | | Qwen2.5-VL-7B (Base) | 68.5 | 50.0 | 48.7 | | VGPO (Ours) | 74.1 | 66.6 | 63.3 | | Qwen2.5-VL-72B | 74.8 | 63.8 | 61.8 |
深度思考:VGPO 的局限与启示
尽管 VGPO 表现优异,但它本质上是一种“启发式引导”。
- 瓶颈在于 Encoder:如果 Vision Encoder 最初就没看清(例如低分辨率下把 '6' 看成 '8'),VGPO 的“强制关注”反而会加剧模型对错误信息的迷信。
- 过度补偿风险:并不是每一推导步都需要看图。在纯纯的逻辑计算阶段强制看图,可能会干扰模型的解题节奏。
总结
VGPO 证明了多模态大模型的性能上限不仅仅取决于预训练规模,更取决于我们在 RL 阶段如何引导模型“眼脑统一”。通过将“看图”作为一种可补偿的奖励信号,VGPO 成功治愈了多模态推理中的注意力涣散症。