本文提出了 ViVa,一种基于视频生成预训练模型(Video-generative Value model)的机器人强化学习价值函数。该方法通过将预训练视频扩散模型 Wan2.2 重新建模,使其能够根据当前多视图观测和机器人本体感知,联合预测未来状态及标量价值。在现实世界的复杂任务(如纸箱组装)中,ViVa 显著提升了策略的成功率和鲁棒性。
TL;DR
在机器人强化学习中,判断当前动作“好不好”往往依赖于价值函数。传统的 VLM 方案由于缺乏对物理动态的感悟,经常在复杂操作中“间歇性失明”。本文提出的 ViVa 通过“借用”视频生成模型的时空建模能力,让机器人在评估当前价值时必须先“想象”一下未来的动作走向。实验证明,这种带预见的价值评估让机器人在组装纸箱等长程任务中,成功率从 58% 飙升至 73%。
痛点深挖:判别式 VLM 的“静态局限”
目前的 Vision-Language-Action (VLA) 模型虽然在语义理解上很强,但在处理机器人操作时存在一个致命伤:缺乏对物理演化的直觉。
- Prior Work 的缺陷:现有的价值模型多是判别式的,它们把每一帧看作独立的切片。就像一个只看过照片的人,很难理解把零件拼歪 1 厘米会对 10 秒后的成败产生多大影响。
- 研究动机:作者认为,价值估算本质上是一个预测未来的问题。如果模型能预测未来场景如何演化,它自然就能更好地判断当前状态是否处于通往成功的正轨上。
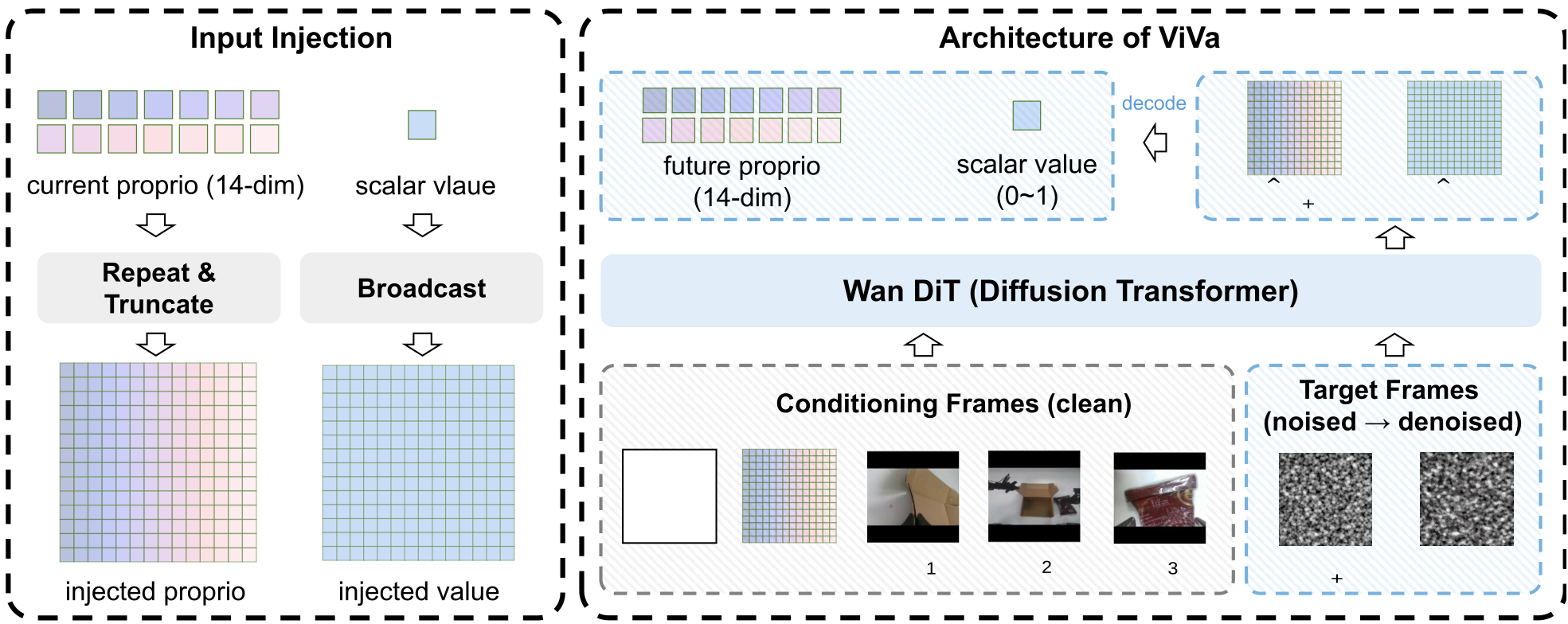
方法论详解:将价值注入潜空间
ViVa 并没有盲目堆叠参数,而是巧妙地将预训练的视频生成器(Wan2.2)改造为一个多模态预测器。
1. 潜空间注入 (Latent Injection)
为了不改动预训练模型的结构,ViVa 将非图像数据(机器人关节位置、标量价值)映射为与视频帧相同维度的 Latent Frames。
- Proprioception (本体感知):通过 Repeat-padding 填充。
- Scalar Value (价值):通过 Broadcast 广播到整个潜帧。
2. 联合预测机制
ViVa 的核心直觉在于:价值估计必须与具身动力学(Embodiment Dynamics)耦合。模型输入的序列包含:
[当前观测图像 + 当前本体感知状态 + 未来本体感知的噪声占位符 + 价值的噪声占位符]
通过 Diffusion Transformer 进行去噪,模型被迫在预测价值的同时,必须思考机械臂在未来 K 步会移动到哪里。
实验与结果:敏锐的故障检测器
在复杂的实物实验中,ViVa 表现出了惊人的“预警”能力。
SOTA 对比:
在纸箱组装(Box Assembly)这一高难度、长路径任务中,ViVa 配合 RECAP 算法,显著优于纯模仿学习方案和基于 VLM 的优化方案。
| 方法 | 成功率 (%) | 吞吐量 (次/小时) | | :--- | :--- | :--- | | Gigabrain-0 (Base) | 53 | 10 | | RECAP (VLM Value) | 58 | 11 | | RECAP (ViVa) | 73 | 14 |
关键洞察:为什么要预测未来轨迹?
下方的实验图表揭示了 ViVa 的优越性。当机器人出现“对齐偏差”或“由于重心不稳导致倾斜”时,ViVa 的价值曲线会迅速出现尖锐的下降(蓝色阴影区),而 VLM 方案则对此几乎无感,依旧盲目乐观。

零样本泛化 (Zero-shot)
最令人兴奋的是,ViVa 在处理从未见过的物体(如折叠裤子,而训练集只有衬衫)时,依然能准确识别出“提起”、“折叠裤腿”、“对齐”等关键里程碑动作,这得益于视频模型中蕴含的通用物理先验。
深度洞察与总结
Takeaway: ViVa 的成功再一次证明了,对于具身智能而言,生成式预训练(Generative Pretraining)提供的是一种更深层的物理世界规律总结。将价值函数从一个简单的分类器提升为一个“想象力引擎”,是解决复杂机器人交互任务的关键。
局限性:
- 单步推理延迟(0.18s)虽优于传统 VLM,但对于极高频的实时闭环控制仍有提升空间。
- 依赖高质量的成功/失败演示数据进行价值标定。
未来展望: 未来的机器人可能会拥有更强大的“世界模型”,不仅仅是预测下一步的图像,而是能够根据当前的价值引导,在潜空间中反复试错,从而在真正动手之前就筛选出最优的操作路径。