本文提出了 VL-Calibration,一种针对多模大模型(LVLMs)推理的解耦置信度校准视觉强化学习框架。该方法通过将置信度拆分为“视觉置信度”与“逻辑置信度”,显著降低了模型的 Expected Calibration Error (ECE),并在 Qwen3-VL 和 InternVL 等模型上实现了 SOTA 性能。
TL;DR
在视觉语言模型(LVLM)的推理过程中,模型经常表现出“一本正经地胡说八道”:即使视觉感知完全错误,它们依然能给出极高的置信度得分。浙江大学的研究团队提出 VL-Calibration 框架,通过将置信度解耦为**视觉(Visual)和推理(Reasoning)**两个维度,并引入基于图像微扰的强化学习信号,成功在 13 个主流榜单上降低了 4 倍以上的校准误差(ECE),同时显著提升了推理准确率。
痛点深挖:为何单位置信度在多模态领域失效?
传统 LLM 的校准方法通常只输出一个全量置信度。然而在 LVLM 中,错误可能源于两个截然不同的阶段:
- 感知的失败:模型由于语言先验,根本没看清图甚至看错了图(例如:把红灯看成绿灯)。
- 推理的失败:模型看清了图,但逻辑推导出了错。
如果将这两者混为一谈,模型就会倾向于过度依赖其庞大的语言先验信息,从而遮盖了视觉上的不确定性,导致严重的视觉幻觉(Visual Hallucination)。
核心方法:VL-Calibration 的三位一体架构
1. 置信度解耦推理 (Decoupled Inference)
VL-Calibration 强制模型在生成 Chain-of-Thought (CoT) 时,分别输出 c_vis(我对自己看到的画面有多自信)和 c_reas(我对自己后续的推导有多自信)。
最终通过**调和平均数(Harmonic Mean)**计算总置信度:
$$ \Phi = \frac{2 \cdot \hat{c}{vis} \cdot \hat{c}{reas}}{\hat{c}{vis} + \hat{c}{reas}} $$
物理直觉:调和平均数具有“木桶效应”,即只要有一个环节(看错或想错)不确定,总置信度就会被大幅拉低。
2. 内在视觉确定性估计 (Intrinsic Visual Certainty)
由于训练数据中缺乏“视觉感知正确与否”的真值标签,作者巧妙地引入了两个物理特征:
- Visual Grounding (KL 散度):对原图进行 80% 的 Patch Masking(遮蔽)。如果模型对图像敏感,输出分布应发生巨大波动(高 KL);若模型在瞎猜(依赖文本先验),遮不遮图结果都一样(低 KL)。
- Internal Certainty (Token 熵):衡量生成描述时的内部确定性。
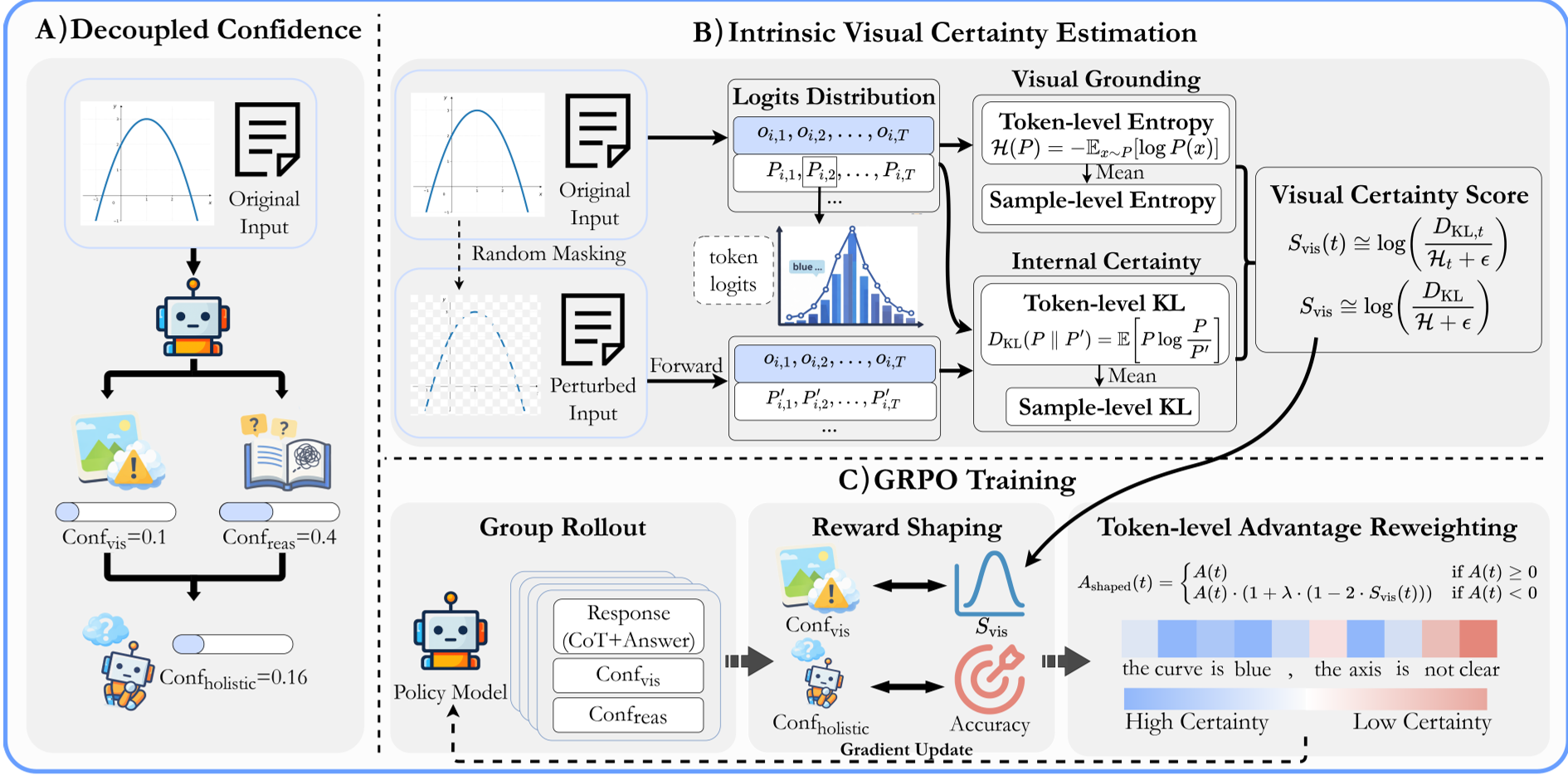
3. Token 级优势重加权 (TAR)
在强化学习(GRPO)阶段,作者提出:对于那些视觉确定性低但模型却大胆给出了错误预测的 Token,施加比普通错误更严厉的惩罚。这种细粒度的信用分配(Credit Assignment)能更有效地抑制幻觉。
实验与结果:全线飘红的 SOTA 表现分析
性能飞跃
在 Qwen3-VL-4B 上的实验显示,VL-Calibration 不仅解决了“自信度”问题,还反哺了“准确率”:
- 平均准确率 (ACC):提升了 2.3% - 3.0%,在 MathVerse 等重视觉任务上提升尤为明显。
- 校准误差 (ECE):从 0.421 惊人地降至 0.098。

消融实验的深层启示
表 3 的消融实验显示,如果去掉视觉确定性估计(VCE),校准效果会大幅跳水。这证明了**外部扰动(KL)和内部熵(Entropy)**缺一不可:仅用熵会导致坍缩,仅用 KL 会导致熵爆炸。
深度洞察:看到与想到的边界
本文最迷人的发现莫过于图 6 的热力图。作者展示了视觉置信度与推理置信度在特征空间的显著分离:模型可能非常确信自己看到了什么,但对如何逻辑推导感到困惑;反之亦然。这种“感知”与“认知”的分离,为未来多模态模型的可靠性设计提供了极具启发性的范式。
局限性与未来
尽管 VL-Calibration 在 30B 规模下表现出色,但在 70B 甚至更大模型上的计算开销(由于需要两次 Forward Passes 计算 KL)仍是实际部署时需要考虑的挑战。未来的方向可能是如何通过轻量化的代理模型或 Hidden States 直接推导这种感知强度。
总结:VL-Calibration 告诉我们,要让 LVLM 变聪明,首先要让它学会“知之为知之,不知为不知”——尤其是在它那双经常“看花眼”的眼睛面前。