This paper systematically evaluates State Space Model (SSM) vision backbones, specifically VMamba, as vision encoders in Large Vision-Language Models (VLMs). Using a controlled LLaVA-style framework, it demonstrates that SSM-based encoders often outperform standard Transformers (ViTs) in spatial grounding and localization tasks while remaining highly efficient and matching SOTA performance in VQA.
TL;DR
While Vision Transformers (ViTs) are the industry standard for Large Vision-Language Models, new research from Stony Brook University suggests we might be overlooking a superior candidate: State Space Models (SSMs). By swapping ViTs with VMamba in a controlled LLaVA setting, the authors found that SSMs provide better spatial grounding and overall performance with fewer parameters. Crucially, they diagnose and fix "localization collapse"—a failure mode where high-resolution models suddenly lose their ability to point at objects.
The "Transformer-Only" Myopia
In the current VLM landscape, the vision encoder is usually a "set it and forget it" component—typically a CLIP-pretrained ViT. However, Transformers are permutation-invariant; they don't "see" 2D structure unless explicitly taught via positional encodings. This often lead to "blurry" spatial reasoning unless we pump up the resolution, which kills inference speed.
The authors' central insight: SSMs like VMamba have 2D spatial biases baked into their architecture through multi-directional scans. Could this architectural "pre-loaded knowledge" make them better at localization than the data-hungry Transformer?
Methodology: The Controlled Swap
To avoid "unfair" comparisons where one model uses more data or better resolution, the team used a strictly matched setup:
- Matched Initialization: All backbones (ViT, MaxViT, MambaVision, VMamba) were pretrained on ImageNet-1K.
- Matched Interface: They extracted features to ensure equal visual token counts ().
- Frozen Backbone: Only the connector and the LLM (Vicuna-7B) were tuned, isolating the encoder's contribution.
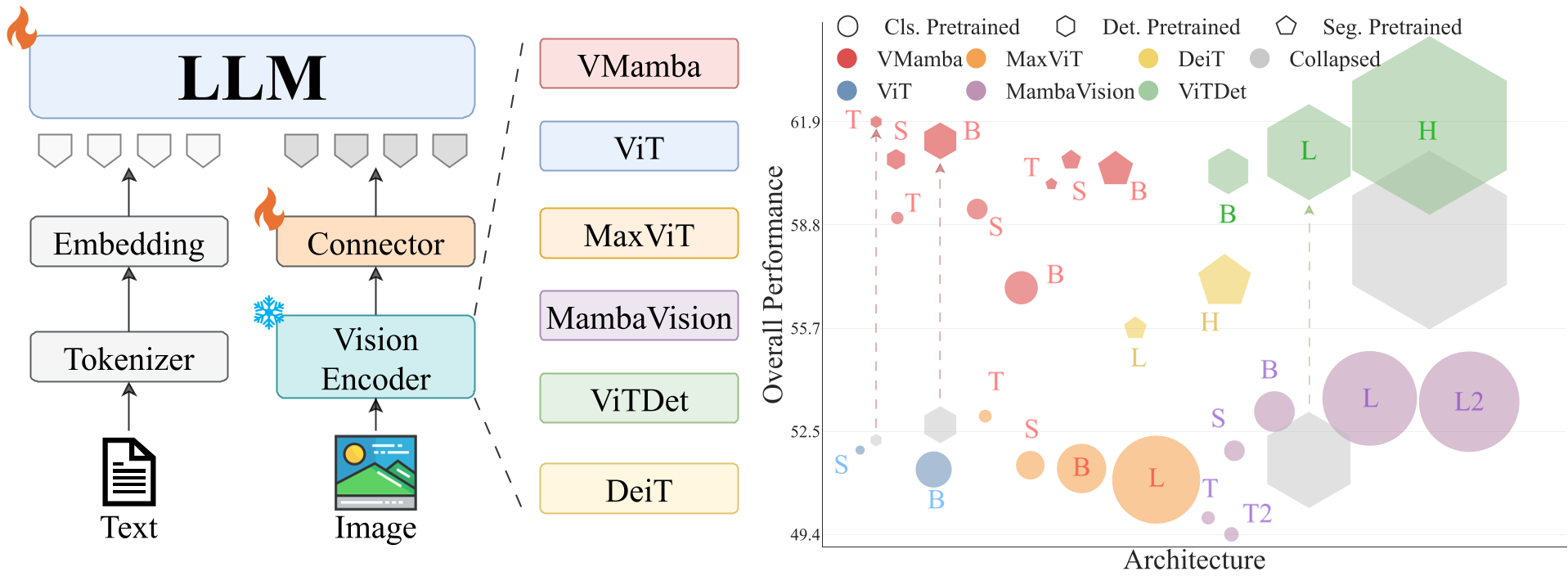
Core Findings: SSMs Win on Grounding
The results were striking. VMamba-Tiny/Small variants consistently outperformed ViT across localization benchmarks (RefCOCO/g/+).
- Why? Quantitative similarity maps showed that VMamba features produce much "sharper" attention peaks on target objects. While ViT spreads its attention across the scene, VMamba's 2D scan mechanism keeps features tightly coiled around spatial structures.
- The Scaling Paradox: Curiously, higher ImageNet accuracy didn't always mean a better VLM. Larger models sometimes "overfit" to classification, discarding useful spatial details that a VLM needs to answer "where" and "how many."
The Case of the Vanishing Bounding Box: Localization Collapse
A major contribution of this paper is the discovery of Localization Collapse. When shifting to high-resolution detection-pretrained backbones (like ViTDet), the models' ability to ground objects would sometimes drop to near zero.

The authors hypothesized this wasn't the encoder's fault, but an Interface Failure. They proposed two "stabilizers":
- Transmission Fix: Upgrading the connector from a 2-layer to a 3-layer MLP.
- Utilization Fix: Forcing Square Geometry (512x512) instead of jagged aspect ratios.
Applying these complementary fixes recovered the "collapsed" models, pushing performance back into SOTA territory.
Depth Insight: Why This Matters
This research challenges the "bigger is always better" scaling law for vision backbones. It suggests that:
- Architecture Matters: The inductive bias of SSMs provides a "free" boost in spatial reasoning that Transformers have to learn the hard way.
- Interface is King: A VLM is only as good as its "connector." If the spatial signal can't pass from pixels to tokens effectively, even a billion-parameter encoder is useless.
Conclusion
The study concludes that VMamba is a strong, size-efficient alternative to the ViT family. For developers building edge-device VLMs or applications requiring high spatial precision (like robotics or GUI navigation), moving away from Transformers toward SSM-based vision encoders might be the next logical step.
Future Outlook: We are likely to see a new generation of "Full-Mamba" VLMs where both the vision and text components leverage state-space efficiency to handle ultra-high-resolution images at a fraction of the current memory cost.