本文提出了 VolDiT,这是首个纯基于 Transformer 的 3D 扩散模型(Diffusion Transformer),用于生成高保真度的体积医学图像。通过将 DiT 架构扩展到 3D 潜在空间并引入时间步门控控制适配器(TGCA),VolDiT 在肺部 CT(LUNA16)和心脏 CTA(TaviCT)数据集上实现了超越传统 U-Net 结构的生成质量和解剖控制力。
TL;DR
传统的 3D 医学影像生成一直被卷积 U-Net 所统治,但其局限于局部感受野,难以把握复杂的全局解剖逻辑。VolDiT 彻底摒弃了卷积骨干,首次将 Diffusion Transformer (DiT) 引入 3D 医学影像领域。配合创新的时间步门控控制适配器 (TGCA),它不仅在生成画质(FID)上刷新了纪录,更在解剖结构的一致性控制上大幅领先传统 U-Net 模型。
核心定位
医学影像生成正在经历从“小模型卷积”向“大模型 Transformer”的范式转移。VolDiT 并非简单的架构平移,它是在 Latent Diffusion 框架内,通过全局 Self-attention 重新定义了体积数据的建模方式,属于典型的 SOTA 刷榜级 + 架构创新 工作。
痛点深挖:为什么 U-Net 逐渐不够用了?
在处理 3D CT 或 MRI 数据时,卷积神经网络(CNN)存在天然的短板:
- Locality Bias (局部偏置):卷积核每次只能看到那一丁点像素,建模心脏或肺部这种宏观器官的完整相干性显得力不从心。
- 感受野受限:为了获得大感受野,U-Net 必须进行多次下采样,但这会导致微小病灶或解剖细节在池化中消失。
- 控制灵活性差:在进行分割图引导生成时,简单的 Concatenation 往往无法让模型精准理解复杂的解剖约束。
Methodology:VolDiT 的核心设计
1. 纯 3D Transformer 骨干
VolDiT 采用 VQ-GAN 将 3D 图像压缩到潜在空间(Latent Space),随后通过 3D Patch Embedding 将体积数据切分为立方体块(Tokens)。这种设计允许模型在每一层都进行全局 Self-attention,确保了生成出来的 3D 器官不仅局部真实,且全局解剖逻辑严丝合缝。
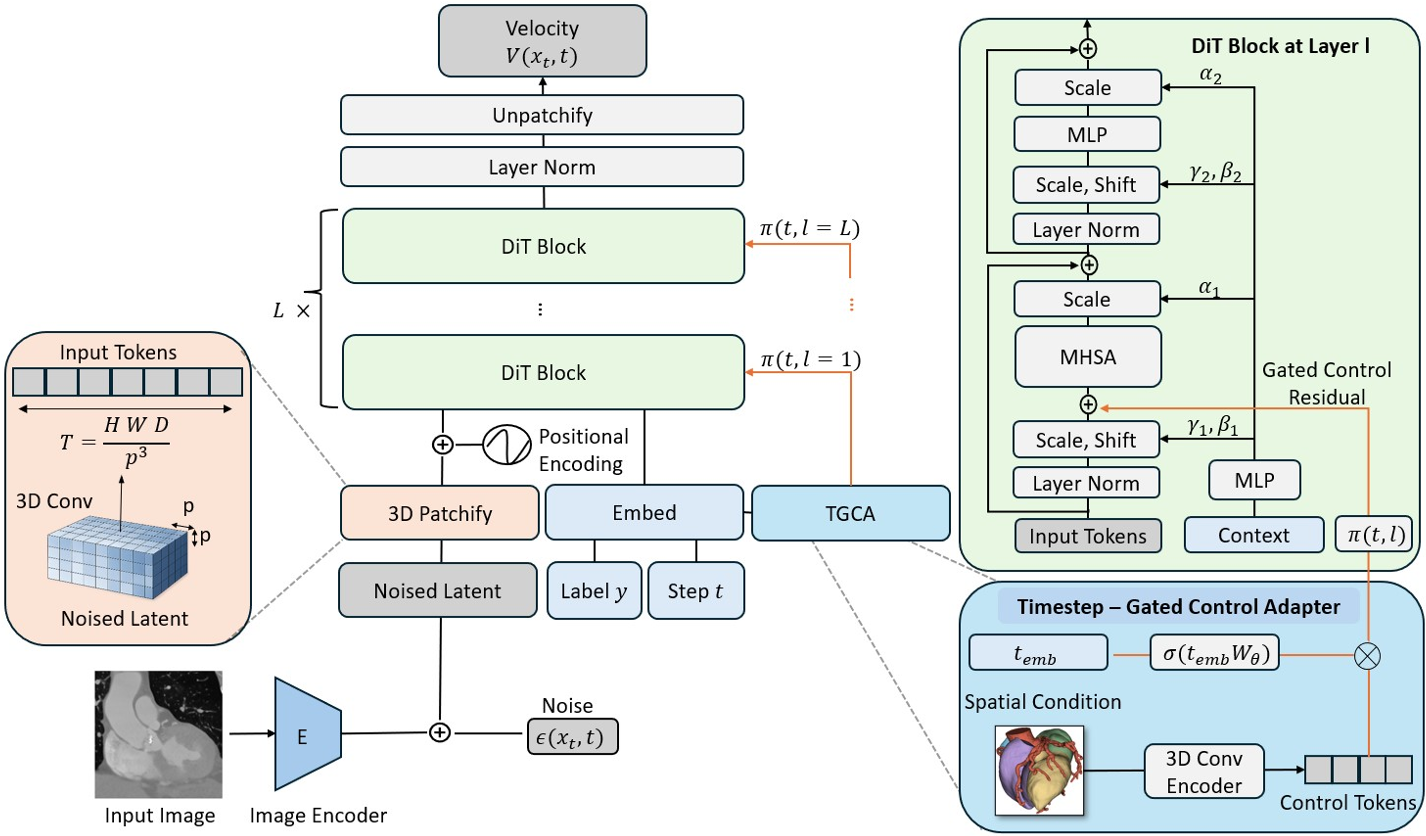 图 1:VolDiT 整体架构逻辑。蓝色部分为 TGCA 控制模块,橙色部分为核心的 3D Transformer 块。
图 1:VolDiT 整体架构逻辑。蓝色部分为 TGCA 控制模块,橙色部分为核心的 3D Transformer 块。
2. TGCA 时间步门控控制
为了让生成过程听从“分割掩码”的指挥,作者设计了 TGCA (Timestep-Gated Control Adapter)。其核心在于:
- Token 化控制:将掩码也转化为 Token。
- 动态门控:利用一个 MLP 学习时间步 的函数,在扩散过程的不同阶段(早期定轮廓,后期修细节)动态调整控制强度。
实验战绩:全方位超越
1. 生成质量对比
在两个大规模数据集 LUNA16(肺部)和 TaviCT(心脏)上,VolDiT 展现了压倒性的优势。特别是在 FID 指标上,VolDiT (L) 在 TaviCT 数据集上达到了 21.4,远超 U-Net LDM 的 36.8。
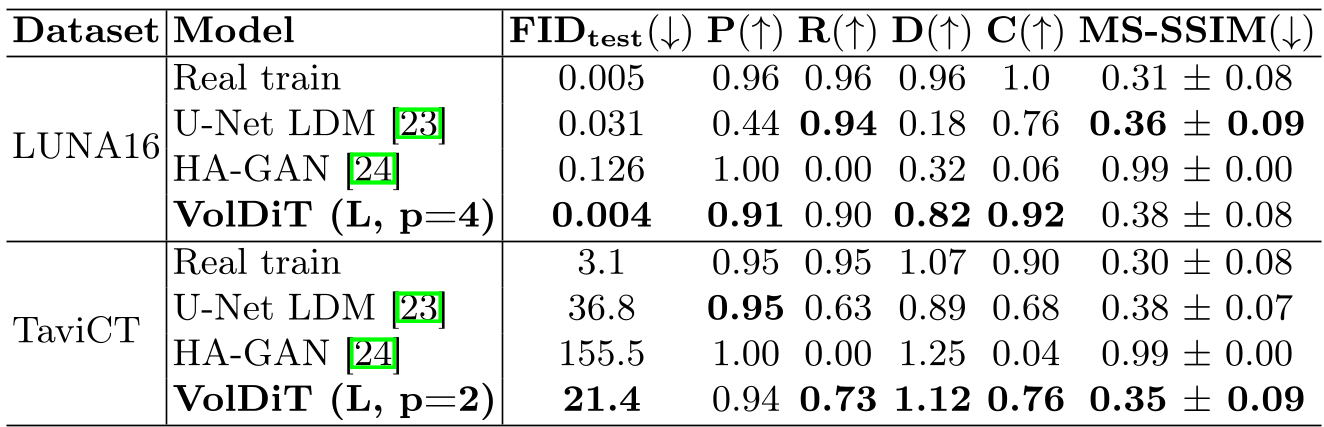 表 1:各模型在 FID、Precision、Recall 等指标上的对比。VolDiT 在 LUNA16 上几乎触及了 Real Data 的下限。
表 1:各模型在 FID、Precision、Recall 等指标上的对比。VolDiT 在 LUNA16 上几乎触及了 Real Data 的下限。
2. 控制精度分析
在解剖对齐实验中(图 3),U-Net 模型生成的图像经常出现缺损或与掩码不匹配的情况(红色方框标注),而 VolDiT 能够精准还原心脏瓣膜和主动脉的解剖结构,Dice 系数提升至 0.94。
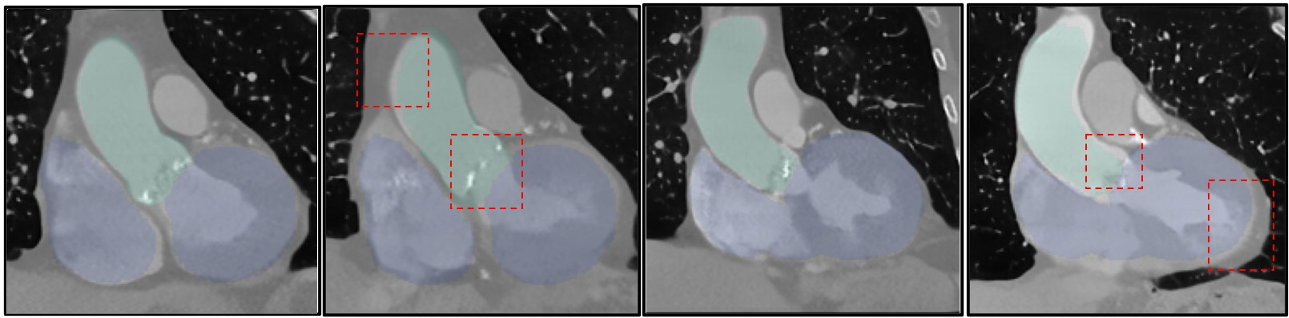 图 3:基于掩码的生成效果展示。VolDiT 在保持解剖拟真度的同时,完美契合了输入条件。
图 3:基于掩码的生成效果展示。VolDiT 在保持解剖拟真度的同时,完美契合了输入条件。
深度洞察:Transformer 是医学影像生成的终局吗?
为什么有效? Transformer 的 Scaling Law 在这里再次生效。与 2D 图片不同,3D 体积数据对空间一致性要求近乎苛刻,全局注意力机制恰恰解决了卷积网络“顾头不顾腚”的问题。
局限性分析:
- 资源消耗:虽然 Patchification 降低了复杂度,但在处理超高分辨率 3D 数据时,显存依然是挑战。
- 训练依赖:论文观察到,由于医学影像样本量相对自然图像较小,超大规模的 DiT-L 模型有时会出现欠训练的情况,这提示我们需要更强大的医学预训练权重。
总结
VolDiT 不仅仅是一个更好的生成模型,它验证了 "Everything is Tokens" 在 3D 医学领域的有效性。它为后续结合文本、临床指标的多模态医学基础模型(Foundation Models)铺平了道路。如果你在寻找下一代医学图像合成的基座,VolDiT 绝对是目前最值得关注的方向。