This paper introduces VOLMO (Versatile and Open Large Models for Ophthalmology), a model-agnostic and data-open framework for developing ophthalmology-specific multimodal large language models (MLLMs). The authors release a compact 2B-parameter model that achieves state-of-the-art performance in eye disease screening, staging, and clinical reasoning across 12 major conditions.
TL;DR
Ophthalmology is a field where "seeing" at the pixel level determines clinical outcomes. While LLMs have conquered text, they have historically failed at the intricate nuances of retinal scans. This paper introduces VOLMO, a 2B-parameter framework that shatters the performance of models ten times its size (like MedGemma-27B) by focusing on domain-specific data-openness, high-resolution visual tiling, and a unique three-stage "Knowledge-to-Reasoning" training pipeline.
The "Blind Spot" of General AI
Current Multimodal LLMs (MLLMs) like GPT-4o or MedGemma face a critical bottleneck in ophthalmology: Resolution and Hallucination.
- Resolution Loss: Standard models downsample images to 224x224 or 336x336. In eye care, a finding like drusen or early nerve fiber thinning might only span a few pixels. Aggressive downsampling effectively "blurs" the diagnosis away.
- Clinical Disconnect: Most models are trained on classification (Disease vs. Normal). Real-world ophthalmology requires synthesis — comparing an OCT scan with a patient’s history of diabetes to decide on a surgery plan.
Methodology: The Three Pillars of VOLMO
VOLMO doesn't just "show" the model images; it teaches it to think like a resident through a staged approach.
1. Ophthalmology Knowledge Pre-training
Using 86,965 image-text pairs extracted from 82 professional journals, the model learns the foundational vocabulary of the eye.
2. Domain Task Fine-tuning
The model is trained on 12 major conditions (Glaucoma, AMD, DR, etc.). Crucially, the authors used a standardized instruction-response schema, converting classic classification datasets into natural language dialogues.
3. Multi-step Clinical Reasoning
This is the "crown jewel." By extracting 913 comprehensive case reports, the model learns to generate:
- Differential Diagnoses
- Most Likely Diagnosis with Justification
- Assessments and Treatment Plans
- Follow-up Care
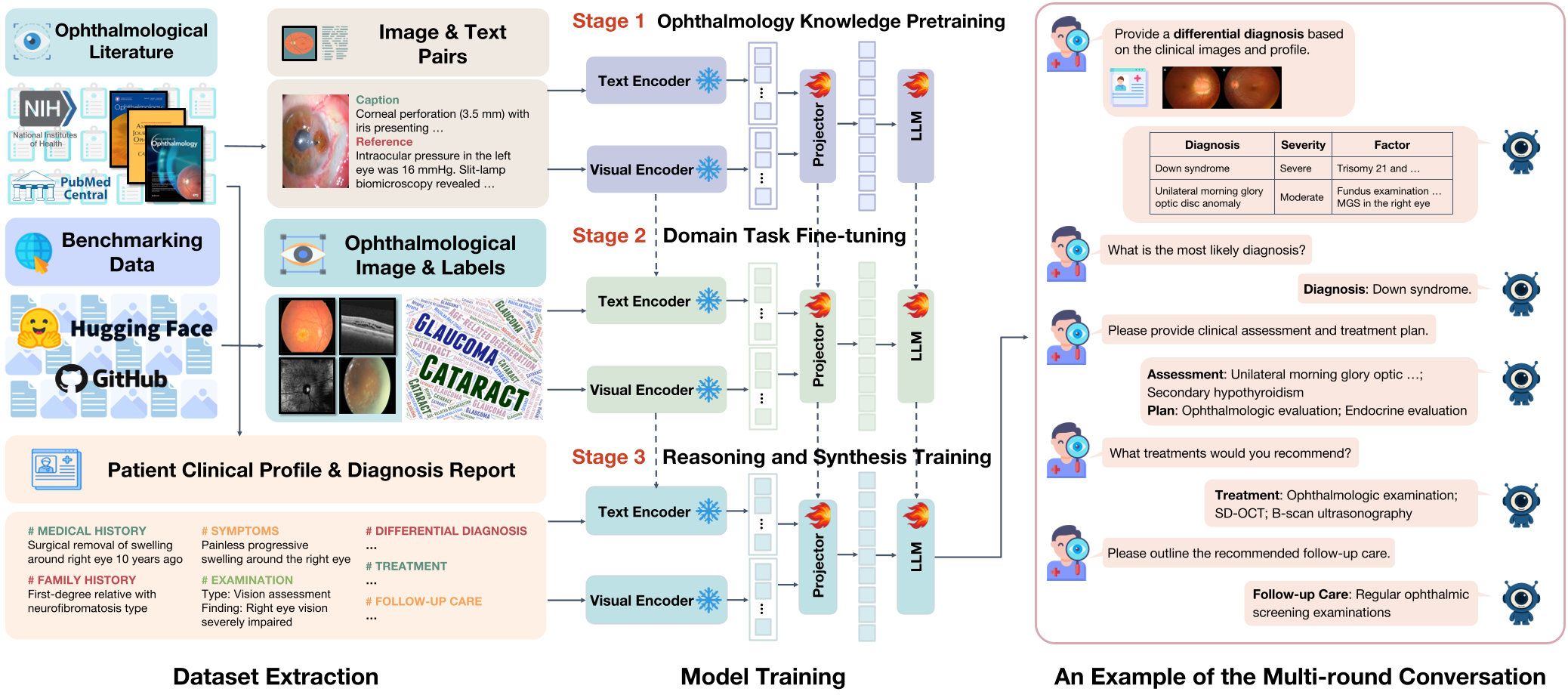
Technical Innovation: Dynamic Resolution
To solve the resolution problem, VOLMO adopts the InternVL backbone. Instead of squeezing a retinal photo into a tiny square, it partitions the image into multiple 448x448 tiles. This "tiling" strategy allows the model to perceive micro-lesions while maintaining a global context of the eye's anatomy.
Experimental Battleground: 2B vs. 27B
The results are a wake-up call for the "bigger is better" crowd.
- Screening Accuracy: VOLMO-2B achieved an 87.41% Macro-F1, crushing LLaVA-Med (38.53%) and even the much larger MedGemma-27B (61.75%).
- Image Description: In manual evaluations by ophthalmologists, VOLMO-2B's descriptions were rated as significantly more concise (4.43/5) and readable than all competitors.
- SOTA Comparison: It outperformed RETFound (the industry-standard vision foundation model) in 8 out of 12 categories, despite RETFound being fine-tuned specifically for each task.
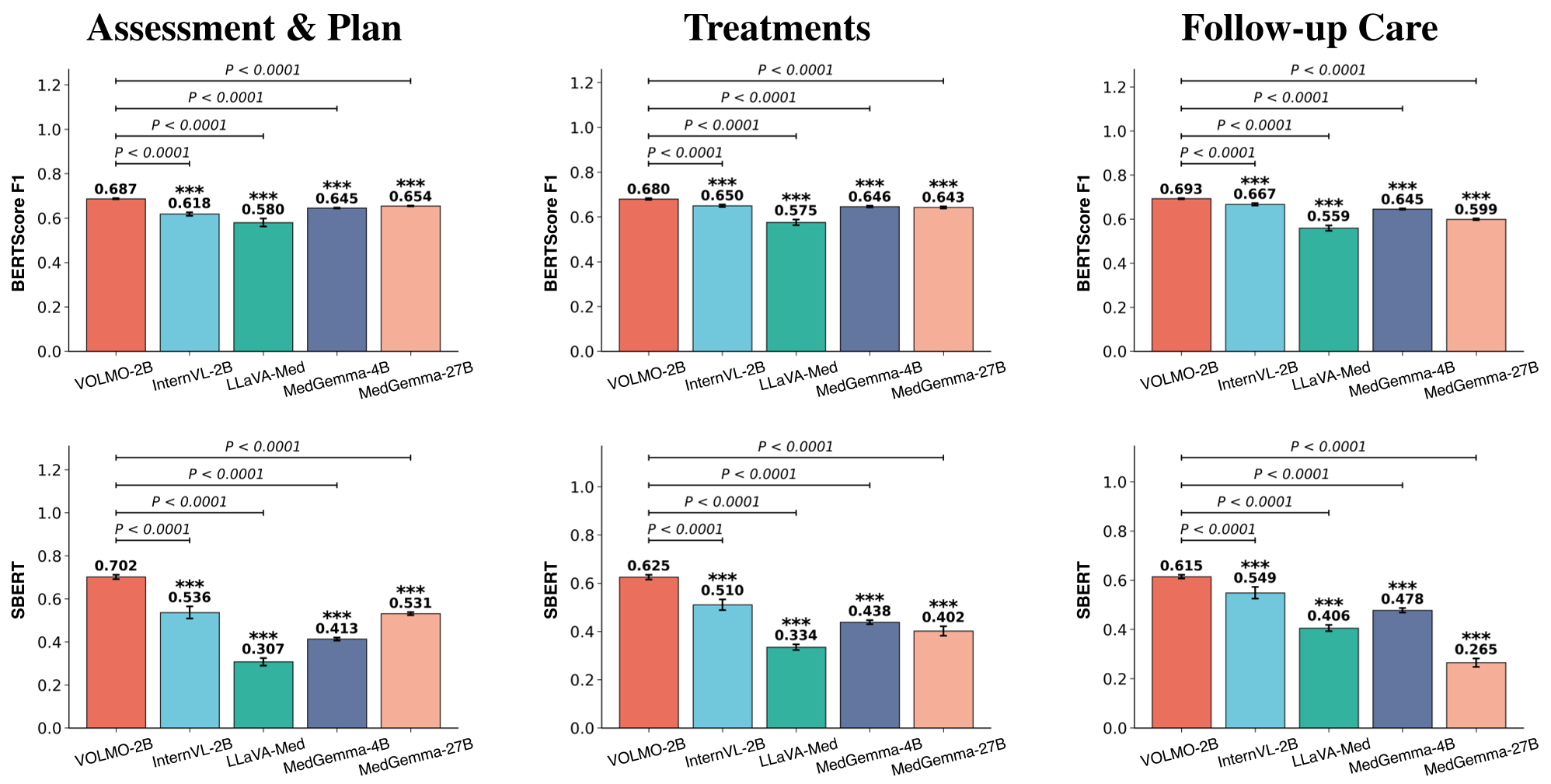
Deep Insight: Why Why Does It Work?
The success of VOLMO stems from Inductive Bias alignment. By using dynamic tiling, the model preserves the spatial Inductive Bias of medical imaging. By using clinical case reports for Stage 3 training, the authors injected "Process Knowledge" (the how of diagnosis) rather than just "Fact Knowledge" (the what of labels).
Conclusion
VOLMO-2B proves that a compact, well-trained model can run on a consumer laptop (RTX 3050) and still deliver specialist-level insights. It marks a shift from proprietary "black box" medical AI toward open, verifiable, and versatile frameworks that can be adapted by local hospitals using their own data.
Limitations to Watch
While VOLMO leads in reasoning, its absolute accuracy in descriptive tasks (2.82/5) remains a challenge, highlighting the ongoing "hallucination" risk in MLLMs when external context (like surgery dates) is missing from the image itself.