开源背后的博弈:为什么 AI 巨头会选择公开他们的“核武器”?
总结
问题
方法
结果
要点
摘要
本文提出了首个分析 AI 竞赛中开源与闭源决策的博弈论模型。研究基于“赢家通吃”的 R&D 竞赛框架,探讨了 AI 团队在离散(全开或全关)和连续(部分开源,如权重开放)操作空间下的战略选择,旨在揭示开源决策背后的理性动机及稳定性。
TL;DR
在 AI 竞赛日趋白热化的今天,Meta 坚持开源 Llama,而 OpenAI 则走向闭源。这背后的逻辑仅仅是情怀吗?来自蒙特利尔大学和 Mila 研究院的最新论文通过博弈论建模指出:开源是一种精密的理性策略。落后者通过开源获取社区红利 来对抗领先者的自研优势,而当这种红利超过对手获得的溢出效益时,开源即成为纳什均衡点。
背景定位
这是首个将“开源/闭源”作为显式博弈动作的 AI 竞赛模型。它不再停留在“开源是否安全”的道德辩论,而是深入“为什么会开源”的商业与地缘政治逻辑,是该领域从定性分析转向定量模拟的里程碑工作。
痛点深挖:领先者的堡垒与追赶者的利剑
在传统的 R&D 竞赛模型中,领先者(如 OpenAI, Google)拥有极高的初始位置 。对于追赶者而言,如果仅仅依靠内部研发,可能永远无法弥合差距。
作者识别出了开源的一对核心矛盾:
- 吸收能力 ():开源可以吸引全球开发者帮你捉虫、适配、优化,直接提升你的技术水位。
- 溢出风险 ():你的代码/权重一旦公开,竞争对手也能直接拿去微调,从而缩短与你的距离。
核心方法论:博弈模型构建
作者提出的效用函数公式非常直观:
eq i} \mu_j(\mathbf{a})$$ 其中 $\mu_i$ 是由于自身动作以及他人动作叠加后的最终进步值。 **模型架构直觉**: 你不仅关注自己跑得多快,更关注你比“最强的对手”快多少。如果你开源能让自己进步 50 分,却让最强对手进步 60 分,那即便你变强了,你的效用也是下降的。 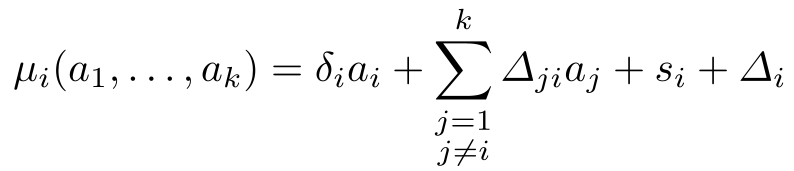 ### 纳什均衡的计算挑战 论文指出,在只有“开”和“关”两种选择的离散场景(Discrete Actions)下,寻找纯策略纳什均衡(PNE)实际上是一个 **NP-hard** 问题。为此,作者巧妙地将其转化为了 **混合整数规划 (MIP)** 问题,利用现成的优化求解器(如 Gurobi)使其在小规模参与者场景下可解。 ## 关键发现:谁更有动力开源? 通过对模型的分析,论文得出了几个极具行业洞察的推论: 1. **落后者的逆袭**:当一个团队落后领先者足够远时,开源的动机显著增强(Corollary 2)。因为此时社区贡献的 $\delta$ 对落后者的边际提升巨大,而对领先者的额外增益($\Delta$)由于基数原因显得微不足道。 2. **社会福利的一致性**:AI 发展的总进步(Social Welfare)与个体团队的开源决策并不总是对齐。只有当开源带来的直接收益超过竞争对手获得的溢出效应时,个体的理性选择才符合社会总利益。 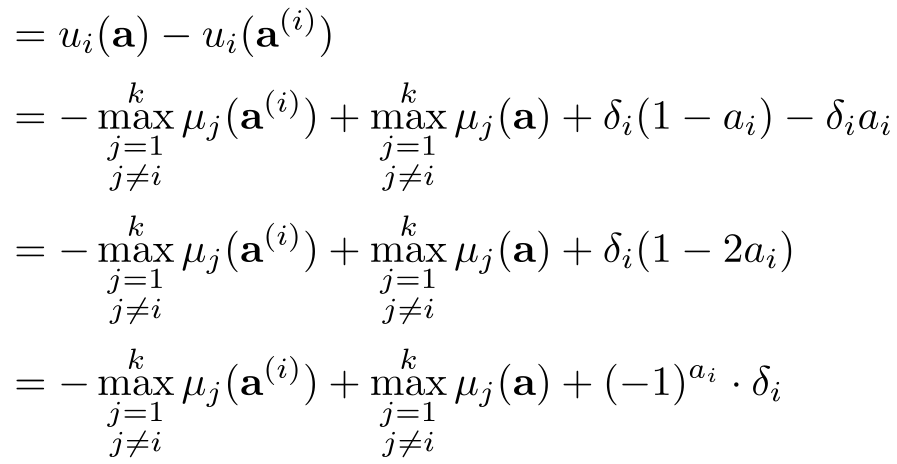 ## 实验与计算逻辑 为了处理“部分开源”(如仅开放权重而非训练数据)的情况,作者将动作空间扩展到了连续区间 $[0, 1]$。在这种情况下,作者证明了 PNE 的存在性。这为分析像 Llama 这种“有限开源”提供了理论基础。 ## 深度洞察与总结 ### 核心贡献 * **数学化描述**:将复杂的 AI 战略决策简化为参数化的博弈方程。 * **复杂度定性**:明确了寻找稳定战略点在计算上的难点。 * **政策启示**:为监管机构(如欧盟)通过减税、特殊豁免等手段人工干预 $\delta$ 值,从而促使巨头走向开源提供了理论支持。 ### 局限性与未来展望 目前模型假设各方收益是**独立的**,但在现实中,两家公司开源可能产生协同效应。作者提出,未来的研究应引入 **贝叶斯博弈(Bayesian Game)**,即在不完全信息下(不知道对手从开源中获益多少)的策略博弈。 **结论**:AI 领域的开源之争并非只是理想主义的火种,它是动态生存竞赛中的数学最优解。理解了这一点,我们就能更好地预判下一场技术巨震的源头。