Workspace-Bench 1.0 is a comprehensive benchmark designed to evaluate AI agents on "Workspace Learning" tasks involving large-scale file dependencies. It features 388 tasks across 5 realistic professional personas, covering 74 file types and over 20,000 files (20GB), setting a new SOTA standard for evaluating cross-file reasoning and lineage tracing.
TL;DR
While AI agents excel at simple "search and summarize" tasks, they are surprisingly incompetent at managing a real professional workspace. Workspace-Bench 1.0 introduces a massive 20GB testbed of 20,476 files across 74 formats to prove it. The verdict? Even the best LLMs (like Claude 3.5 Opus) struggle to navigate the "messy" reality of file versions and cross-document dependencies, achieving an average pass rate of just 47.4%.
The Problem: The "Data Association Gap"
Current benchmarks like GAIA or OSWorld treat the world as a series of isolated API calls or clean text chunks. In reality, a Product Manager or a Backend Developer works in a "knowledge graveyard":
- Deeply Nested Folders: Finding
requirement_final_v2.docxhidden in three layers of archives. - Heterogeneous Formats: Connecting a chart in a
.pptxto a specific cell in a.csvand a discussion in an.eml(email). - Lineage Tracing: Knowing that
report_v1is obsolete becausereport_finalexists.
This paper argues that there is a fundamental Data Association Gap: agents can see files but cannot understand the relationships between them.
Methodology: Simulating the Mess
The researchers didn't just dump files; they built High-Fidelity Relational Workspaces.
- Persona-Driven Simulation: Five roles (e.g., Logistics Manager, AI Researcher) with unique directory structures.
- Hybrid Content: Real-world papers from arXiv and repos from GitHub mixed with "grounded" LLM-generated artifacts like meeting notes and emails.
- Dependency Graphs: Each of the 388 tasks is mapped to a ground-truth graph of required files.
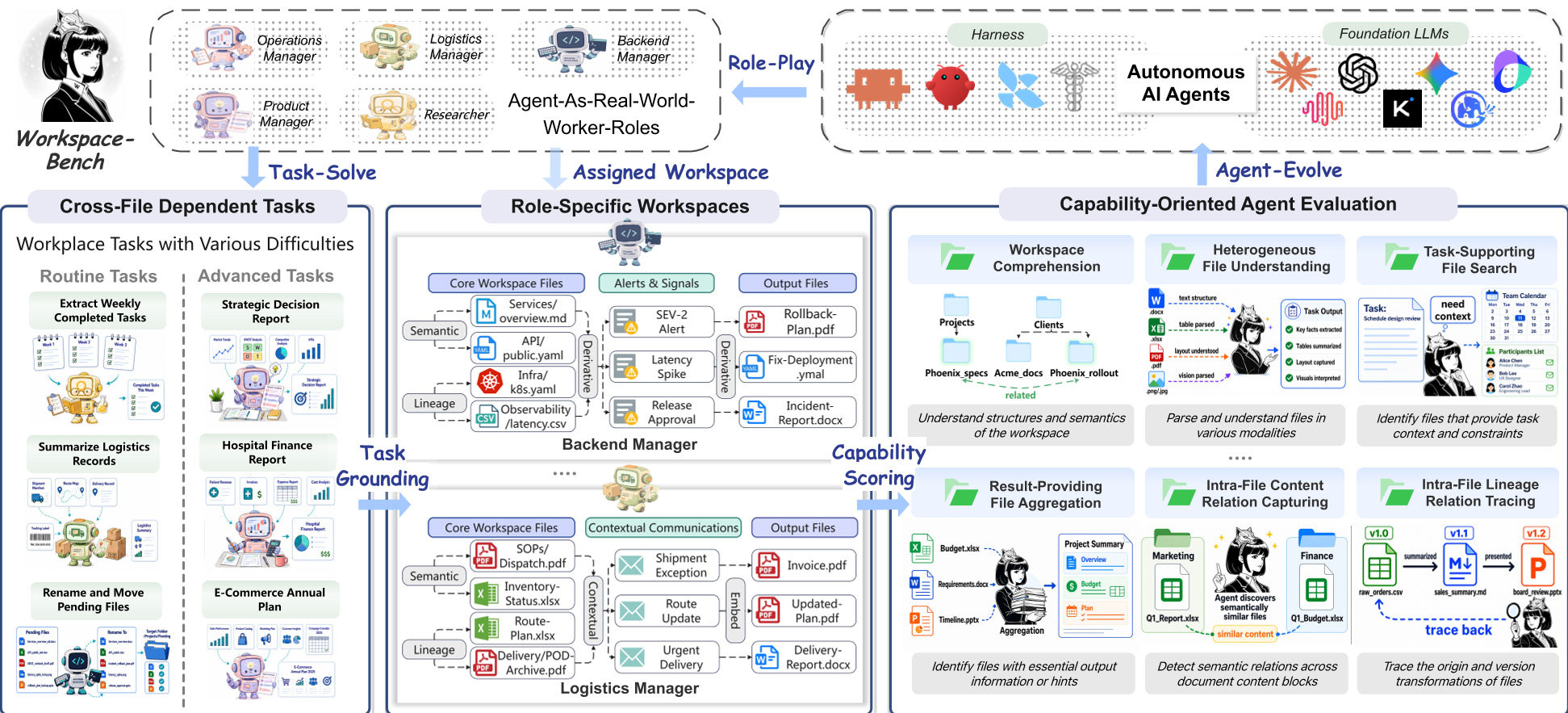 Figure: The hierarchy of the benchmark, moving from atomic skills to complex workspace reasoning.
Figure: The hierarchy of the benchmark, moving from atomic skills to complex workspace reasoning.
The Benchmark Results: A Reality Check
The study evaluated 28 combinations of "Agent Harnesses" (like ClaudeCode, OpenClaw, and Hermes) and LLM backbones.
1. Complexity is the Agent-Killer
Performance correlates inversely with task difficulty. On "Easy" tasks (simple edits), agents are okay (~57%). On "Hard" tasks involving lineage tracing and heterogeneous files, they collapse to ~40%.
2. The Harness Matters
Using the same model (Opus 4.7), different harnesses yielded wildly different results. OpenClaw performed best by decoupling planning from tool execution, while others fell into "meaningless retry loops," consuming millions of tokens without finishing the task.
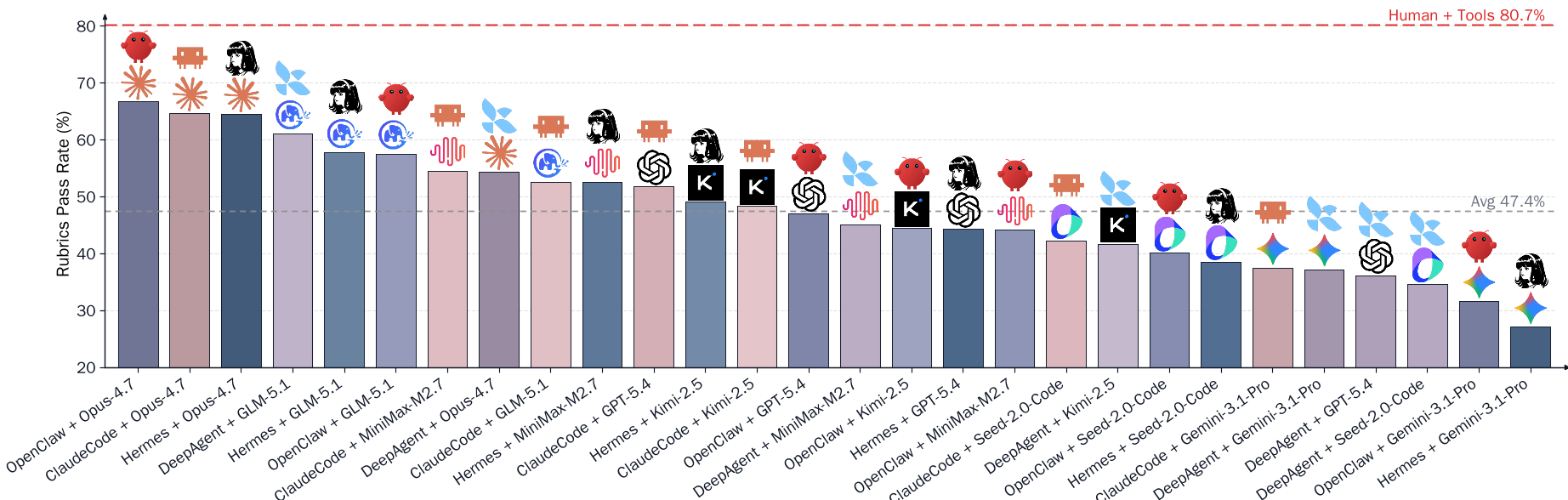 Figure: Ranking of 28 agent configurations. Note the massive gap between the best agent and the human baseline.
Figure: Ranking of 28 agent configurations. Note the massive gap between the best agent and the human baseline.
Deep Insights: The Five Stages of Workspace Learning
The authors propose a roadmap for how agents evolve:
- L0-L1: Passive execution (the "Chatbot" stage).
- L2-L3: Dependency Reasoning & Discovery (the "Investigator" stage). This is where current SOTA agents are currently stuck.
- L4: Workspace-Native Self-Evolution. The agent lives in your system and learns how you organize data over time.
Critical Analysis & Takeaways
The most damning finding is the Error Analysis: Most failures (Missing Content and Reasoning Errors) stem from the agent's inability to "recall deeply embedded information" across multiple files.
- Limitation: The benchmark currently focuses on internet-company roles; expansion to legal or medical workspaces would be a logical next step.
- Future Work: To bridge the Data Association Gap, we need harnesses that don't just "search" but "index" the semantic and temporal relationships of a workspace before starting a task.
The Bottom Line: Until agents can differentiate between config_old.yaml and config.yaml using nothing but context and metadata, they won't be ready to take over our professional workflows.