本文提出了 WorldAgents,这是一个利用 2D 基础图像模型(如 Flux.2)和视觉语言模型(VLM)构建 3D 世界模型的智能体框架。该方法通过多智能体协作(导演、生成器、验证器),将 2D 模型的生成能力转化为生成具有高度 3D 一致性的真实、广阔可探索场景的能力。
TL;DR
慕尼黑工业大学(TUM)的研究团队在最新论文中提出了 WorldAgents。该研究挑战了一个核心假设:虽然 2D 基础模型(如 Flux, Imagen)是在扁平图像上训练的,但它们是否已经“内化”了 3D 物理世界的规则?通过构建一套由 VLM 驱动的导演、生成器和验证器组成的智能体系统,WorldAgents 成功从 2D 模型中提取出了连贯、可自由导航的 3D 高斯泼溅(3DGS)场景。
背景定位:从“画匠”到“造物主”
当前的 3D 生成领域正处于十字路口。一方面,显式 3D 数据(如 ShapeNet)极其稀缺;另一方面,虽然 2D 基础模型拥有惊人的想象力,但它们通常是“空间文盲”,在连续生成时容易产生严重的几何冲突。
WorldAgents 的核心 Insight 是:不要试图重新训练模型去理解 3D,而是通过一套严密的“智能体管理流程”,强迫现有的 2D 模型在 3D 物理约束下进行创作。
核心机制:三位一体的智能体架构
WorldAgents 将场景生成看作一场由 AI 智能体导演的电影拍摄:
1. VLM 导演 (Director Agent)
它负责“脑补”整个房间的布局。它不会盲目地让生成器画图,而是根据当前已有的视野,逻辑性地提出建议:“现在向右转,在金属墙面旁边加一个散发蓝光的数码控制面板”。这种语义上的连续性避免了自回归生成中常见的“语义漂移”。
2. 图像生成器 (Generator Agent)
这是系统的“执行手”。它不仅仅是做 Text-to-Image,而是进行 3D 引导的序贯局部重绘 (Inpainting)。
- 它先将已生成的视图重建为暂时的 3D 场景。
- 移动虚拟相机,得到一张带有缺失区域(遮挡产生的黑洞)的重投影图。
- 仅让基础模型填充这些“黑洞”。
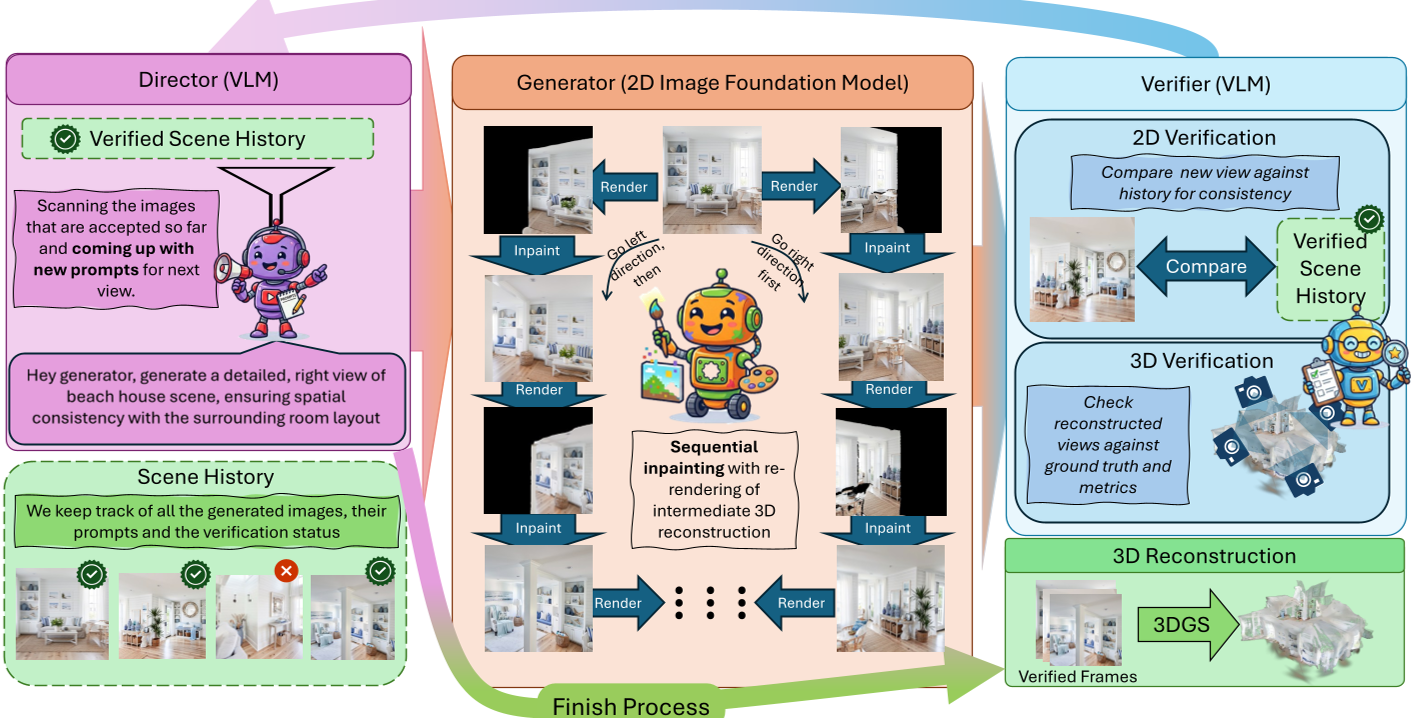
3. 两阶段验证器 (Verifier Agent) - 判官的角色
这是保证 3D 一致性的关键。
- 2D 语义检查:VLM 检查新生成的画面有没有崩坏。
- 3D 几何审核:将新帧并入 3D 场景,如果导致整体重建指标(PSNR 等)大幅下降,说明这一帧存在几何幻觉,果断打回重做。
实验战绩:让场景真实可探索
在与 SOTA 方法(如 Text2Room)的对比中,WorldAgents 生成的场景在物体密度和细节保真度上表现优异。

消融实验数据说话:
- 仅使用生成器:CLIP-IQA 评分 0.60。
- 加入导演和三维感知重绘:评分飙升至 0.89。 这证明了“3D 约束下的序贯重绘”是保持世界稳定性的核心武器。
深度洞察:为什么这很重要?
WorldAgents 的成功标志着 3D 生成范式的转型:从“数据驱动”转向“推理驱动”。它不再寄希望于喂给模型更多的 3D 扫描数据,而是利用 VLM 强大的推理能力(Reasoning)来监督生成过程中的物理逻辑。
虽然目前该方法在生成超大规模室内外场景时仍受限于显存和推理时间(约 25 分钟生成一个场景),但它为未来的“无限世界”生成(World Models)指明了道路——通过智能体化的反馈环,2D 幻觉终将收敛于真实的 3D 物理规律。
总结
WorldAgents 不仅仅是一个 3D 生成工具,它更是一次深刻的科学探索,确认了超大规模 2D 预训练模型中确实隐藏着通往三维世界的钥匙。
Takeaway: 未来的 3D 内容创作可能不再需要专业的 3D 建模师,而只需要一批优秀的“AI 导演”和“AI 质检员”。