WorldCam is a foundational interactive 3D gaming world model based on a Video Diffusion Transformer (DiT). It introduces camera pose as a unifying geometric representation to achieve precise 6-DoF action control and long-horizon 3D consistency, setting new SOTA benchmarks on the proposed WorldCam-50h dataset.
Executive Summary
TL;DR: WorldCam is a breakthrough in interactive world modeling that bridges the gap between "video generation" and "game engines." By using camera pose as a unified geometric language, it allows for pixel-perfect action control and the ability to revisit locations in a 3D environment without the world "morphing" or "forgetting" its layout.
Background: While models like Genie or Gaia have shown that AI can simulate playability, they often feel "soupy"—actions are approximate, and turning around often reveals a completely different world. WorldCam treats the AI not just as a frame-predictor, but as a geometrically-aware renderer.
The Problem: The "Geometry Gap" in World Models
Current interactive models treat your "W-A-S-D" keys as simple text or category labels. If you press "Forward" and "Right" simultaneously, traditional models might struggle because they don't understand the underlying physics of a screw motion.
Furthermore, long-term consistency is the "Achilles' heel" of autoregressive models. Without a global coordinate system, the model has no way to "anchor" a building at a specific coordinate. If you walk away and come back, the building is gone—this is known as the Exploration-Consistency Trade-off.
Methodology: Geometry as the First-Class Citizen
WorldCam solves this through two primary technical innovations:
1. Action-to-Camera Mapping via Lie Algebra
Instead of linear approximations, WorldCam represents user actions as velocities in Lie algebra . This allows the model to integrate translation and rotation jointly.
- Why it works: It captures the physical coupling of movement. A curve is treated as a single geometric transformation rather than two separate shifts in X and Rotation.
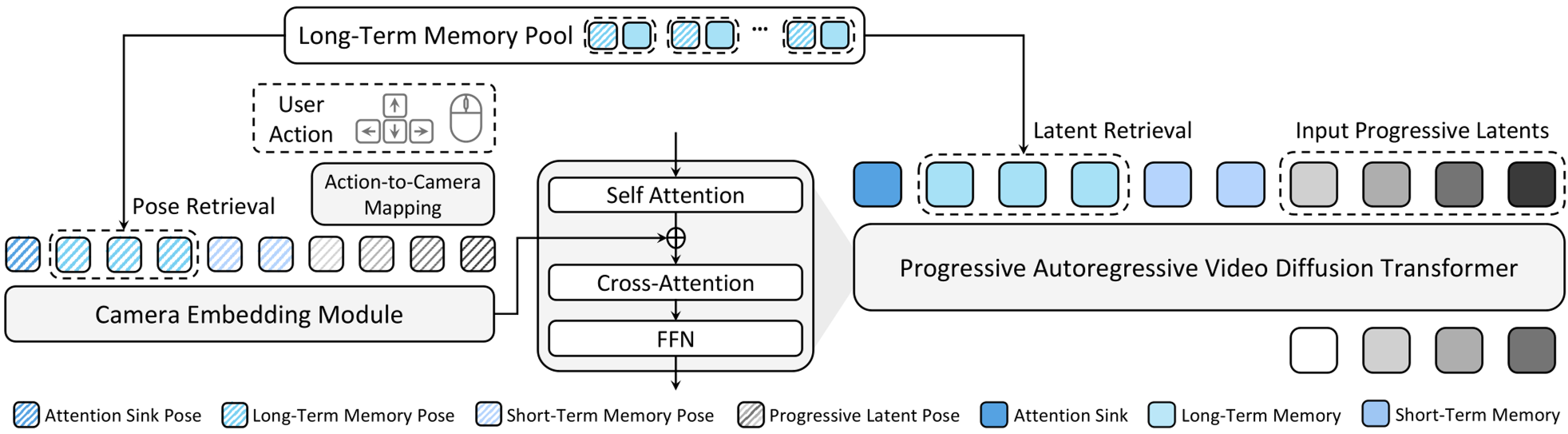 Figure 1: The WorldCam architecture uses Lie Algebra for action mapping and a Memory Pool for 3D consistency.
Figure 1: The WorldCam architecture uses Lie Algebra for action mapping and a Memory Pool for 3D consistency.
2. Pose-Anchored Long-Term Memory
Because the model tracks a precise global camera pose , it can maintain a "Spatial Map" of latents.
- The Workflow: When a user moves, the system searches the memory bank for the "nearest" previous camera poses.
- Retrieval: It uses a hierarchical strategy—first finding nearby positions, then aligning for orientation. These retrieved "memories" are fed back into the Transformer, forcing it to render what it saw before.
Experiments & Results: Real Gaming Precision
The researchers introduced WorldCam-50h, a massive dataset of human gameplay from titles like Counter-Strike and Xonotic, complete with ground-truth camera trajectories.
Performance Highlights:
- Action Control: WorldCam achieved a 16.3% improvement in camera extrinsic error compared to the previous best (GameCraft).
- Consistency: In "Loop" tests (where the player returns to the start), WorldCam’s DINO Similarity jumped to 0.88 (vs. 0.59 for baselines), proving the world stays stable.
- Visual Fidelity: By using "Attention Sinks" (keeping early frames as anchors), the model avoids the "visual drift" or blurriness typical of long-horizon AI videos.
 Figure 2: Qualitative comparison showing WorldCam's superior ability to maintain architecture and lighting over long durations.
Figure 2: Qualitative comparison showing WorldCam's superior ability to maintain architecture and lighting over long durations.
Critical Analysis & Future Outlook
Takeaway: WorldCam proves that "Video Generation" is essentially "Unstructured 3D Rendering." By re-introducing classical robotics/CV concepts like the manifold into the Diffusion Transformer, we get the best of both worlds: the realism of AI and the precision of a game engine.
Limitations:
- Inference Speed: While faster per-step than some models, it isn't "instant" yet. Future work using Distillation (like SDXL-Turbo styles) will be needed for 60FPS gameplay.
- Static Worlds: The current model focuses on static environments. Adding dynamic NPCs or destructible environments while maintaining the same 3D consistency is the next "Grand Challenge."
Final Thought: We are rapidly approaching a future where "Game Development" involves describing a world and its physics, and the AI generates the "Engine" on the fly. WorldCam is a significant step toward that "Generative Reality."