本文提出了 WorldCam,一种基于视频扩散 Transformer (DiT) 的交互式游戏世界基础模型。该方法引入了相机位姿(Camera Pose)作为统一的几何表示,实现了精确的动作控制和长效 3D 一致性,在动作保真度和视频生成质量上达到 SOTA 水平。
TL;DR
传统的视频生成模型往往把用户操作(如按下 W 键或移动鼠标)当成一种模糊的“暗示”,但在真正的游戏引擎中,这些操作对应着严格的物理位姿变换。WorldCam 彻底改变了这一现状:它首次将**相机位姿(Camera Pose)**作为统一的几何表征,不仅实现了精准到 6-DoF 的动作响应,更解决了生成视频在长距离交互中“走回来场景变了”的 3D 一致性顽疾。
核心痛点:为什么 AI 依然造不出完美的游戏世界?
尽管视频扩散模型(Video DiT)能生成震撼的视觉效果,但在“交互性”和“一致性”上存在天然短板:
- 动作失准:现有模型(如 Matrix-Game)直接注入原始动作信号,缺乏对 $SE(3)$ 几何流形的理解,导致复杂的复合动作(如一边侧移一边转身)生成的轨迹极其不自然。
- 遗忘效应:当你操控角色在一个大地图转一圈回到起点时,模型由于缺乏长效记忆,生成的初始位置往往已经物是人非。
- 误差累积:自回归生成过程中,微小的偏差会随时间放大,导致画面逐渐崩溃或 UI 扭曲。
核心技术路线
1. 从 Lie Algebra 到 SE(3):物理真实的动作映射
WorldCam 不再使用简单的线性近似,而是在李代数 $se(3)$ 中定义动作空间。通过矩阵指数映射(Exponential Map),将用户的速度向量 $\mathbf{V}$ 和角速度 $\boldsymbol{\omega}$ 转化为流形上的变换矩阵。这种方法能够完美建模“螺旋运动(Screw Motion)”,即平移与旋转的深度耦合。
2. 位姿锚定的长期记忆(Pose-Anchored Memory)
这是解决 3D 一致性的神来之笔。WorldCam 维护一个存储已生成隐变量(Latents)的记忆池,每个片段都带有其全局位姿记录。
- 检索机制:当相机再次靠近已知坐标时,模型会根据位置和视角方向检索最相关的历史 Latents。
- 几何配准:这些历史记录被拼接回当前的 Context 中,强制模型在生成新帧时参考“过去的自己”,确保场景不走样。
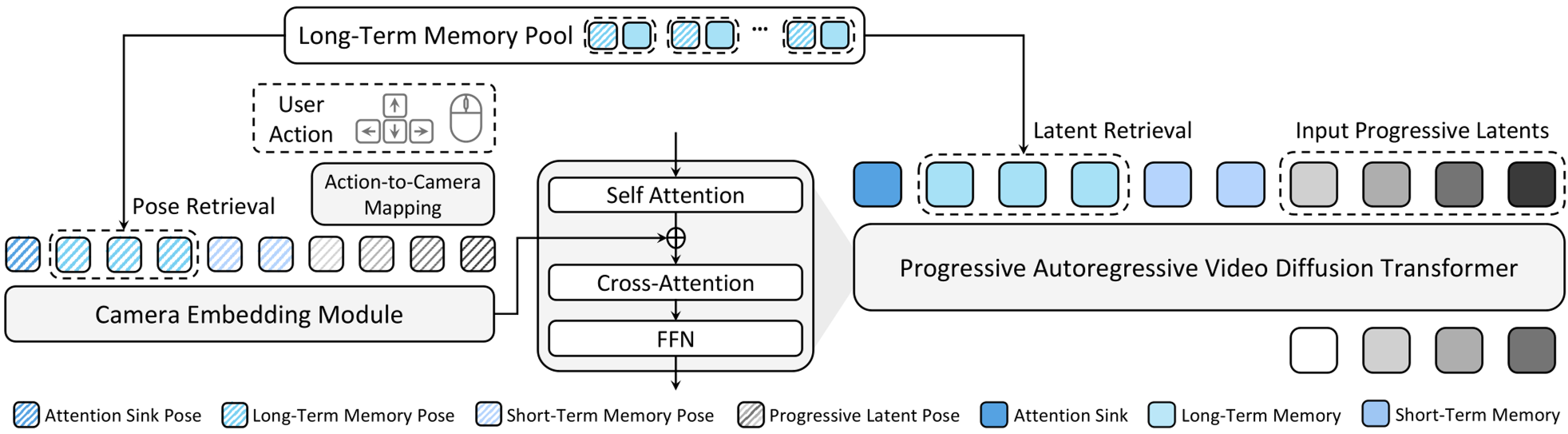 图 1:WorldCam 总体架构。它将动作转化为位姿,通过长期存储池和 Attention Sink 机制维持世界的物理稳定性。
图 1:WorldCam 总体架构。它将动作转化为位姿,通过长期存储池和 Attention Sink 机制维持世界的物理稳定性。
3. 渐进式自回归推理与 Attention Sink
为了保证生成的流畅性,作者采用了渐进式噪声调度(Progressive Noise Scheduling)。在一个推理窗口内,不同帧处于不同的去噪阶段,这既保证了时间上的连续性,也允许模型修正之前的细微错误。同时,引入 Attention Sink(注意力池化)机制,固定初始帧作为全局锚点,有效防止了长时生成的漂移。
实验战绩与视觉呈现
精准的动作跟踪
在下表中可以看到,WorldCam 在平均相对位姿误差(RPE)上显著优于此前的 SOTA 模型 GameCraft。特别是在旋转精度上,李代数建模带来的优势让误差几乎减半。
 表 1:在动作控制与视觉质量上的定量对比。
表 1:在动作控制与视觉质量上的定量对比。
长征式的 3D 一致性
如下图所示,当模型经历 200 帧的长距离重访后,WorldCam 生成的画面依然能保持地形和建筑架构的连续,而 Yume 等对比策略则出现了明显的场景漂移。
 图 2:定性对比。注意看在回转过程中,WorldCam 对走廊布局的保持能力。
图 2:定性对比。注意看在回转过程中,WorldCam 对走廊布局的保持能力。
行业启示:WorldCam-50h 数据集的贡献
学术界长期苦于高质量游戏动作数据集的匮乏。作者随本文发布了 WorldCam-50h。
- 规模:3000 分钟(50 小时)真实人类游玩数据。
- 多样性:涵盖《反恐精英》等复杂 3D 环境,标注了伪地面真值的相机位姿和详细的文本描述。
- 意义:相比于 Minecraft 数据集,它更真实地反映了 3D 空间中的交互动态。
总结与反思
WorldCam 为构建“AI 游戏引擎”提供了一套扎实的几何底座。它告诉我们:纯粹的数据驱动或许能生成美丽的像素,但只有引入几何常识,才能构建真正的“世界”。 当然,目前该模型在实时性上仍有提升空间(单步耗时约 0.52s),如何通过蒸馏技术(Distillation)实现端到端的 30+ FPS 生成,将是通往“全 AI 驱动游戏”的最后一公里挑战。
关键词:Interactive World Model, Video DiT, Lie Algebra, 3D Consistency, SE(3).