The paper introduces WorldMAP, a teacher-student distillation framework for Vision-Language Navigation (VLN) trajectory prediction. It leverages generative world models as "supervision engines" to create structured semantic-spatial pseudo-labels, enabling a lightweight student model to achieve SOTA results on Target-Bench.
TL;DR
Current embodied agents struggle to predict reliable navigation paths from a single image. WorldMAP fixes this by using a "Teacher" world model to imagine the future, map it into a structured 3D space, and plan a "perfect" path. This path becomes the training data for a "Student" model, which can then navigate expertly using only a single observation—without needing the heavy world model at runtime.
Core Achievement: A massive 42.1% reduction in Final Displacement Error (FDE) compared to top-tier models like Gemini-3-Pro.
The Motivation: Why "Imagination" Isn't Enough
Recent breakthroughs in generative world models (like Sora or Gen-3) allow AI to "imagine" what lies around a corner. However, for a robot, just seeing a plausible future isn't the same as planning a safe path. Typical Vision-Language Models (VLMs) suffer from:
- Instability: They often propose paths through walls or furniture.
- Geometric Drift: Visual imaginations are often "dreamy" and lack the metric precision required for physical movement.
WorldMAP asks a transformative question: What if we use these "dreams" to generate high-quality training labels instead of using them live?
Methodology: The Teacher-Student Decomposition
The framework follows a World-Memory-Action-Perception decomposition, inspired by Yann LeCun’s vision for autonomous machine intelligence.
1. The Slow Teacher (Offline Supervision)
The Teacher model takes a single image and generates multiple "future video" streams. It then:
- Reconstructs the Scene: Uses monocular depth estimation to back-project pixels into 3D.
- Grounds the Task: A VLM identifies the target (e.g., "The vending machine") and obstacles across all generated views.
- BEV Planning: All evidence is flattened into a Bird's-Eye-View cost map. It then uses the Fast Marching Method (FMM) to find the most efficient, collision-free path.
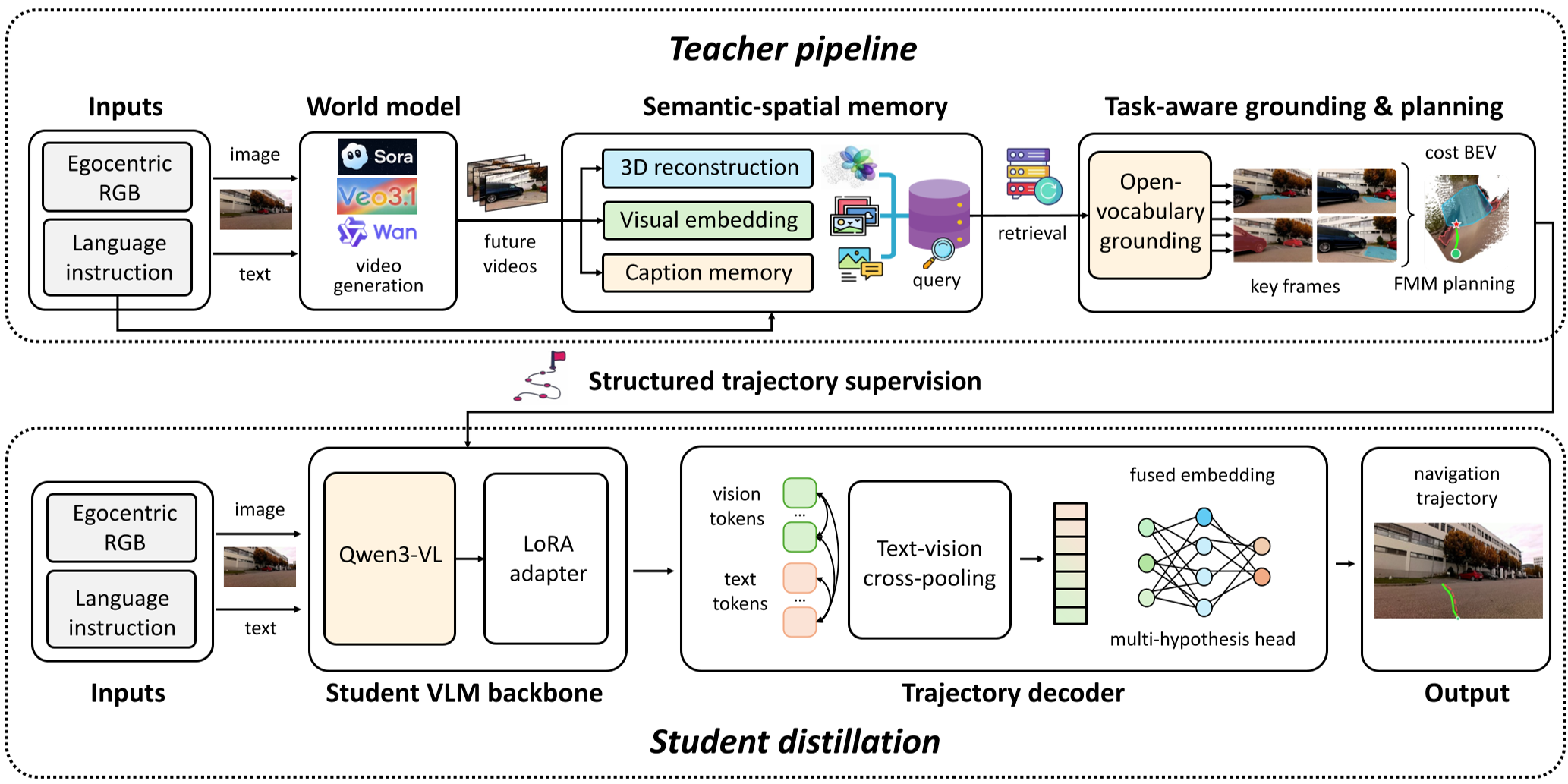 Fig 1: The architecture showing the world-model-driven teacher producing pseudo-labels for the student.
Fig 1: The architecture showing the world-model-driven teacher producing pseudo-labels for the student.
2. The Fast Student (Online Execution)
The Student is a lightweight VLM (like Qwen3-VL-8B). During training, it learns to mimic the Teacher’s planned paths. At test time, it doesn't need to generate videos or complex maps; it looks at an image and immediately outputs the best trajectory hypotheses.
Experimental Results: Lifting Small Models to Pro Levels
The researchers tested WorldMAP on Target-Bench, a rigorous real-world benchmark for mapless path planning.
| Method | ADE ↓ | FDE ↓ | DTW ↓ | | :--- | :--- | :--- | :--- | | Gemini-3-Pro (Proprietary) | 51.27 | 67.19 | 31.63 | | MindJourney (World-Model Aug.) | 152.41 | 250.17 | 84.84 | | WorldMAP (Ours) | 42.06 | 38.87 | 31.95 |
The most striking result is the FDE (Final Displacement Error). While even proprietary giants like Gemini-3-Pro struggle to stop precisely at a target, WorldMAP's distilled student hits the mark with significantly higher accuracy.
 Fig 2: Comparison on Target-Bench. Note how WorldMAP (blue) follows floor geometry while others drift through obstacles.
Fig 2: Comparison on Target-Bench. Note how WorldMAP (blue) follows floor geometry while others drift through obstacles.
Critical Insight: Distillation vs. Test-Time Reasoning
A key takeaway from the paper is the "failure" of MindJourney (a method that uses imagination at test time). The authors found that consuming generated frames verbatim during navigation can introduce hallucinations and noise.
By contrast, WorldMAP uses Distillation. It filters the "dreams" through a geometric planning bottleneck (the BEV cost map) before teaching the student. This ensures the student learns only the grounded, consistent navigational structure and ignores the generative artifacts of the world model.
Conclusion & Future Work
WorldMAP proves that the greatest value of world models in robotics might not be as "thinking" components, but as "data factories." They bridge the gap between static datasets and the infinite complexity of real-world environments.
Limitations: The system still depends on the initial world model's ability to generate somewhat plausible views. In entirely alien or structurally complex multi-level buildings, the geometric reconstruction might still fail. However, the move toward persistent semantic-spatial structure marks a major step toward reliable, embodied AI.