本文提出了 WorldMAP,一种用于具身智能导航轨迹预测的“教师-学生”蒸馏框架。该方法利用生成式世界模型(Generative World Models)合成未来视角,并将其转化为结构化的语义空间图层,从而为轻量级 VLM 学生模型提供高质量的路径规划伪标签。在 Target-Bench 评测中,WorldMAP 在 ADE 和 FDE 指标上分别超越 SOTA 基线 18.0% 和 42.1%。
TL;DR
在自动驾驶和具身智能领域,如何让机器人仅凭“一眼”和一条指令就规划出准确路径?哈工大、清华及中关村实验室等机构联合提出的 WorldMAP 给出了一种新思路:不再让昂贵的世界模型在导航时“现想”未来,而是让它在训练阶段充当“教师”,通过合成虚幻但逻辑自洽的未来场景,教导轻量级的学生模型掌握空间感。
痛点深挖:为什么“想象”很难直接变成“行动”?
当前的 Vision-Language Navigation (VLN) 领域存在两个极端:
- 直接预测派:利用大模型(如 GPT-4, Qwen-VL)直接出坐标。由于缺乏对物理空间和障碍物的显式认知,模型经常给出“穿墙”或“瞬移”的离谱路径。
- 世界模型派:通过想象未来的画面(Look-ahead reasoning)来辅助预测。但问题在于,生成的图片是像素,机器人需要的是坐标。且在测试时运行生成模型,速度慢如蜗牛,且容易被生成图中的微小语义错误误导。
作者认为:世界模型生成的“未来”不应是证据(Evidence),而应是监督(Supervision)。
核心机制:World-Memory-Action-Perception 分解
WorldMAP 模仿了 LeCun 提出的自主机器智能架构,将导航任务拆解为四个阶段:
1. 教师模型:从“像素”到“地图”
教师模型并不直接输出轨迹,而是经历了一场“脑内模拟”:
- 构建世界:利用生成模型产生未来视角的视频流。
- 语义记忆:将视频帧存入语义空间存储器(Semantic-Spatial Memory),识别出指令中提到的“目标”(Targets)和“避障点”(Obstacles)。
- 显式规划:将所有信息投影到 BEV(俯视图)平面,构建代价地图(Cost Map),并使用 FMM (Fast Marching Method) 算法算出的一条物理上最合理的路径。
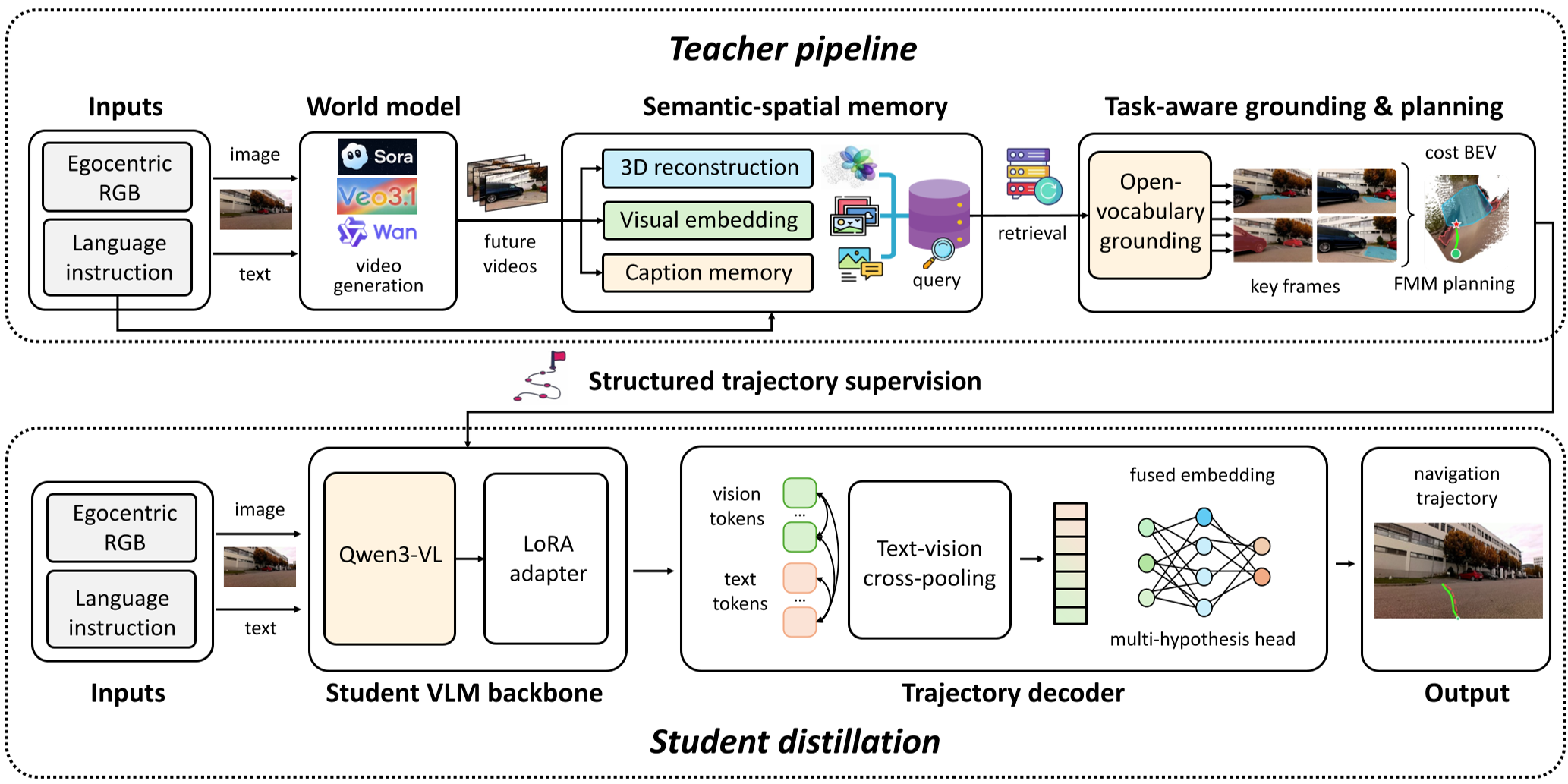
2. 学生模型:轻量化蒸馏
学生模型摒弃了沉重的生成推理,仅由一个轻量级 VLM 骨干和多假设轨迹预测头组成。它的任务是“背诵”教师算出的路径,学习如何在看到单张图片时,就能直觉化地感知到隐藏在视角背后的空间拓扑。
实验战绩:以小博大的胜利
在 Target-Bench 这一严苛的真实场景数据集上,WorldMAP 展现了统治级的表现:
- 精度碾压:相比于最强的闭源模型 Gemini-3-Pro,WorldMAP 的终点位移误差(FDE)减少了 42.1%。
- 小模型逆袭:经过蒸馏后的 8B 开源模型(Qwen3-VL),在导航表现上竟然超越了计算量大数倍的 GPT 系列。
从可视化结果可以看出,WorldMAP 生成的轨迹(红色)能够极好地贴合地面几何形状,避开转角处的障碍,而基线模型(如 o3)往往会发生漂移或对目标定位不准。
深度洞察:快慢系统论
WorldMAP 的设计哲学实际上契合了心理学中的 系统 1(快思考)与系统 2(慢思考):
- 教师模型是“慢系统”:深思熟虑、耗费算力去想象未来、建立地图并规避障碍。
- 学生模型是“快系统”:在部署时通过直觉(前馈算力)迅速做出反应,但这种直觉是由慢系统长期教育累积而成的。
局限与展望
尽管 WorldMAP 在单次观测导航中取得了突破,但它目前在处理动态障碍物(如行人移动)和多层建筑等极度复杂的拓扑结构时还存在挑战。未来,如何将这种“生成式监督”扩展到长程探索(Long-horizon Exploration)任务,将是具身智能走向实用的关键。
总结一句话: 世界模型的价值,在于它能为机器人提供一种“即使没去过,也能想明白”的虚拟演练场,并以此培养出更聪明的单帧决策直觉。