X-Cache:突破自回归世界模型实时推理瓶颈的“跨块”缓存技术
本文提出了 X-Cache,一种针对自动驾驶等 Few-step(少步数)自回归世界模型设计的跨 Chunk 模块缓存加速方法。该方法通过在连续生成的视频块(Chunks)之间重用 DiT 模块的残差,在 X-World 生成模型上实现了 71% 的模块跳过率和 2.6 倍的端到端推理加速。
TL;DR
小鹏汽车 AI Infra 团队开源了 X-Cache,一种专为少步数(Few-step)自回归视频扩散模型设计的训练加速方案。它不依赖去噪步间的冗余,而是巧妙利用视频序列中相邻 Chunk 之间的物理连续性进行残差重用。该方法在保证自动驾驶仿真精度(SSIM 0.999+)的同时,实现了 2.6x 的推理加速。
背景:世界模型的“快”与“准”之争
在自动驾驶领域,世界模型(World Models)被寄予厚望,用于构建闭环仿真环境。然而,SOTA 模型如 X-World 通常采用自回归架构且需要处理 7 摄像头环视视频,推理延迟极高。为了实时交互,业界普遍采用 Few-step 蒸馏(如将去噪步压缩至 4 步)。
痛点在于: 现有的加速技术(如 DeepCache, FlowCache)大多基于去噪步骤间的相似性。但在 4 步去噪下,每一步的结构更新都非常巨大,强行缓存会导致严重的伪影;且自回归场景下的 Action 输入是非平滑的,传统方法难以应对。
核心直觉:物理场景的连续性是有价值的
X-Cache 的核心 Insight 是:虽然去噪步骤间的冗余消失了,但连续生成的视频块(Cross-chunk)之间存在极强的物理冗余。自动驾驶场景中,车辆行驶是连续的,模型在生成第 个块和第 个块时,DiT 内部的残差分布非常接近。
技术详解:X-Cache 如何工作?
1. 结构与动作感知指纹 (Dual-Metric Gating)
X-Cache 并非盲目跳过模块,而是通过一个精密的“门控机制”来判断:
- 3D 空间指纹:对 Latent 在 F, H, W 三个轴上进行子采样,捕捉空间结构相似性。
- 动作通道 (Action-aware):将驾驶动作向量直接引入指纹比对。如果驾驶员突然急转弯或刹车,指纹会迅速发生剧变,强制模型进行完整计算。
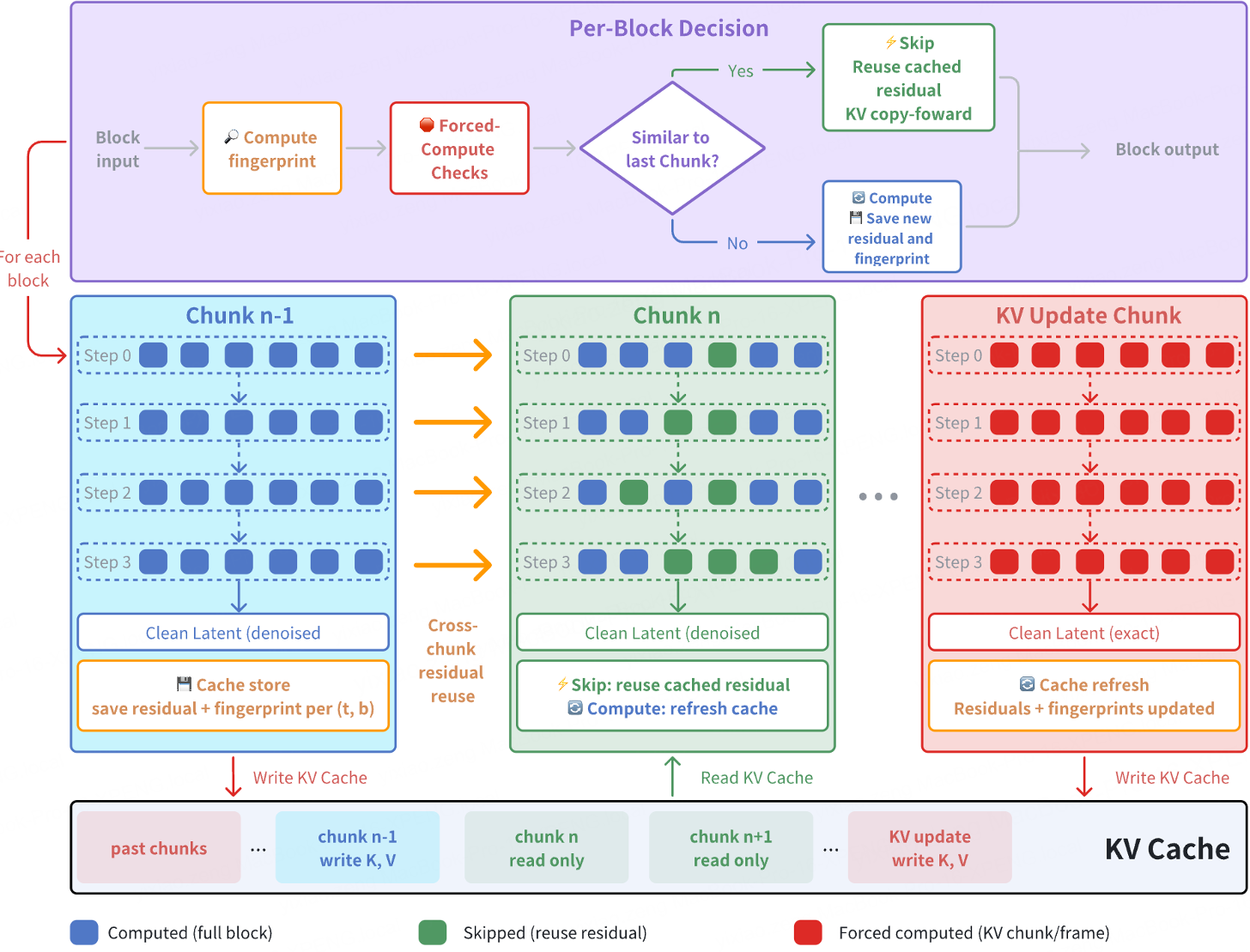
2. KV 更新帧的“绝对领域”
自回归推理中最怕“误差累积”。X-Cache 设计了一个硬性安全开关:KV Update 帧保护。 在需要向持久化 KV Cache 写入新 Key-Value 的前向传递中,X-Cache 会无条件关闭缓存,进行全量计算。这确保了作为后续生成“根基”的 KV 缓存是绝对纯净的。
3. 自适应阈值 (Adaptive Threshold)
由于 DiT 不同层的敏感度不同,X-Cache 引入了 EMA(指数移动平均)来动态学习每一层的相似度阈值。这避免了手动调参,让模型能自动在简单场景(高速直行)多跳过模块,在复杂场景(闹市穿行)多计算。
实验结果:无损加速的典范
团队在真武 810E (PPU) 加速器上进行了验证,针对城市道路、高速增长和掉头等极端场景进行了压力测试。
- 加速比:实现了约 71% 的模块跳过率,DiT 部分 wall-clock speedup 达到 2.6x - 2.7x。
- 保真度:从下图可见,X-Cache 生成的画面(中)与全量计算(左)几乎无异,残差图(右)放大了 20 倍才看到极细微的边界差异。

总结与思考
X-Cache 的成功证明了:在模型效率优化中,寻找正确的冗余轴比算法本身的复杂性更重要。
- 局限性:目前主要在自动驾驶内部分布数据上验证,对于剧烈的环境突变(如进入隧道瞬间)的鲁棒性仍需更多极端案例(Corner Cases)支撑。
- 未来展望:这种跨块缓存的思想完全可以推广到其他交互式生成领域,如实时 AI 游戏生成或交互式视频编辑。
关键词:X-Cache, 自动驾驶世界模型, 自回归视频扩散, DiT 加速, 推理优化